package 'tidyverse' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\cd-desk\AppData\Local\Temp\Rtmpa25X7Y\downloaded_packages
install.packages("moderndive")
package 'moderndive' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\cd-desk\AppData\Local\Temp\Rtmpa25X7Y\downloaded_packages
install.packages("caret")
package 'caret' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\cd-desk\AppData\Local\Temp\Rtmpa25X7Y\downloaded_packages
install.packages("dslabs")
package 'dslabs' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\cd-desk\AppData\Local\Temp\Rtmpa25X7Y\downloaded_packages
# Just for the slidesinstall.packages("thematic")
package 'thematic' successfully unpacked and MD5 sums checked
The downloaded binary packages are in
C:\Users\cd-desk\AppData\Local\Temp\Rtmpa25X7Y\downloaded_packages
You will have some but perhaps not others.
Libraries
I’ll just include them upfront.
library(tidyverse)library(moderndive)library(caret)library(dslabs)# Just for the slideslibrary(thematic)theme_set(theme_dark())thematic_rmd(bg ="#111", fg ="#eee", accent ="#eee")
Setup
We will work with a wine dataset that is enormous.
id country description designation
Min. : 1 Length:89556 Length:89556 Length:89556
1st Qu.: 32742 Class :character Class :character Class :character
Median : 65613 Mode :character Mode :character Mode :character
Mean : 65192
3rd Qu.: 97738
Max. :129970
points price province region_1
Min. : 80.00 Min. : 4.00 Length:89556 Length:89556
1st Qu.: 87.00 1st Qu.: 17.00 Class :character Class :character
Median : 89.00 Median : 25.00 Mode :character Mode :character
Mean : 88.65 Mean : 35.56
3rd Qu.: 91.00 3rd Qu.: 42.00
Max. :100.00 Max. :3300.00
region_2 taster_name taster_twitter_handle title
Length:89556 Length:89556 Length:89556 Length:89556
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
variety winery year
Length:89556 Length:89556 Min. :1995
Class :character Class :character 1st Qu.:2010
Mode :character Mode :character Median :2012
Mean :2011
3rd Qu.:2014
Max. :2015
# A tibble: 3,774 × 16
id country description designation points price province region_1 region_2
<dbl> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr>
1 53 France Fruity and… La Fleur d… 85 15 Bordeaux Bordeau… <NA>
2 136 France This wine'… <NA> 91 50 Bordeaux Saint-É… <NA>
3 419 France A smooth, … <NA> 89 20 Bordeaux Graves <NA>
4 477 France An interes… <NA> 92 65 Bordeaux Pomerol <NA>
5 573 France Fruity and… <NA> 89 14 Bordeaux Bordeau… <NA>
6 575 France This is a … <NA> 89 14 Bordeaux Bordeau… <NA>
7 576 France From a Gra… Les Terras… 89 37 Bordeaux Saint-É… <NA>
8 578 France A ripe per… Château Je… 89 15 Bordeaux Bordeaux <NA>
9 792 France The 45% Ca… La Sérénit… 90 30 Bordeaux Médoc <NA>
10 795 France This is th… Divin de C… 90 35 Bordeaux Saint-É… <NA>
# ℹ 3,764 more rows
# ℹ 7 more variables: taster_name <chr>, taster_twitter_handle <chr>,
# title <chr>, variety <chr>, winery <chr>, year <dbl>, bordeaux <lgl>
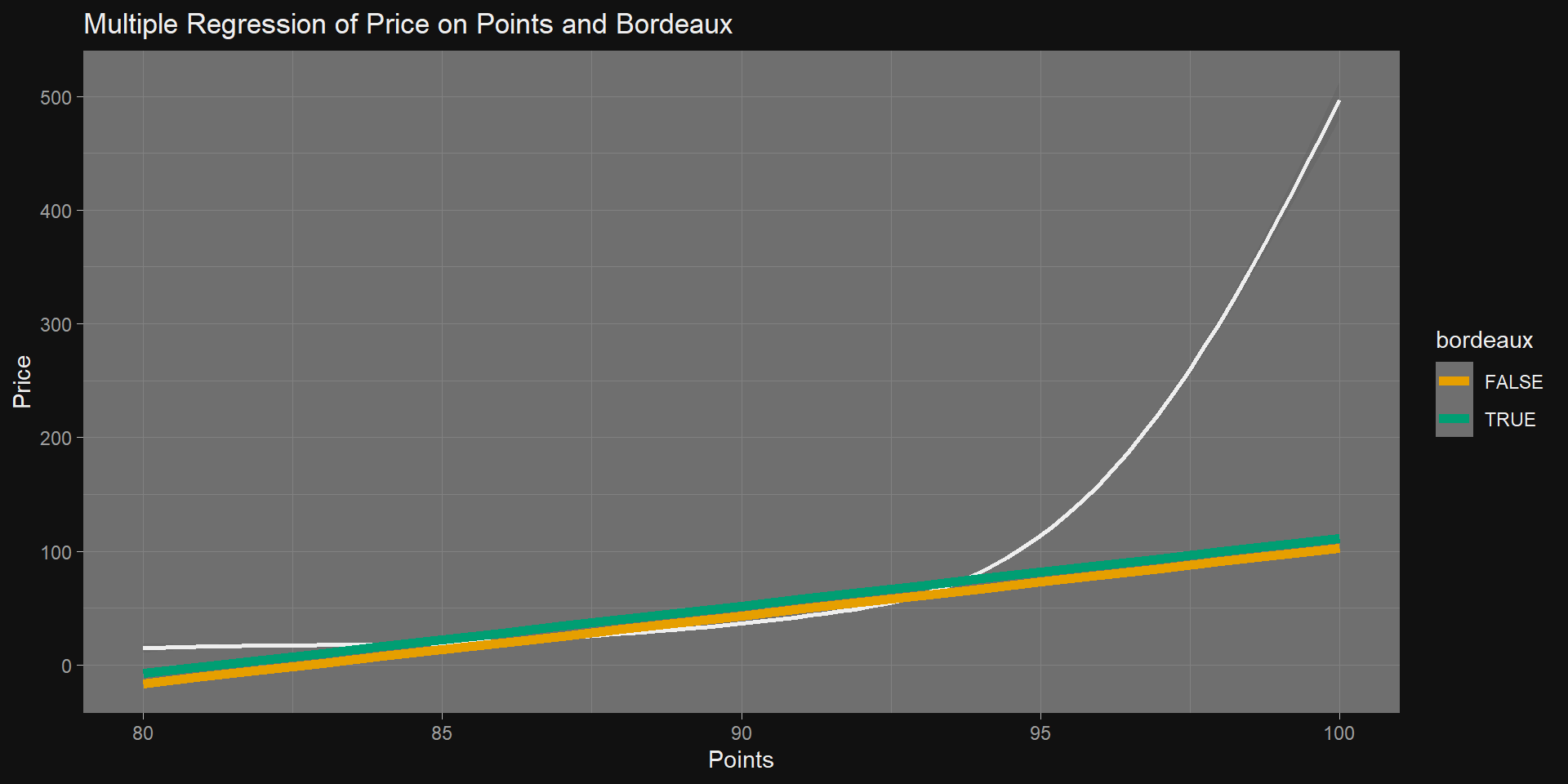
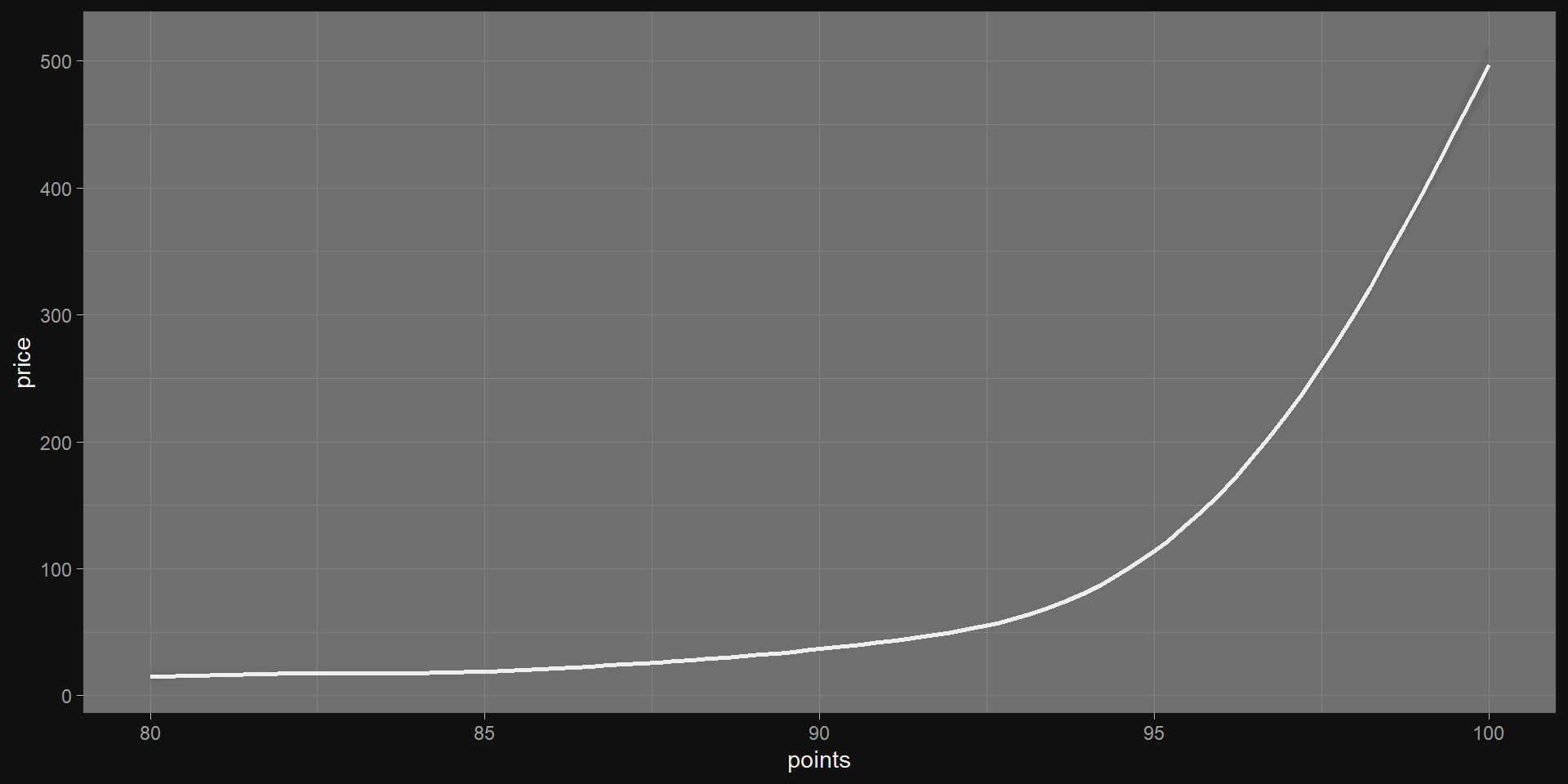
Regress
Take a quick regression model over the wine.
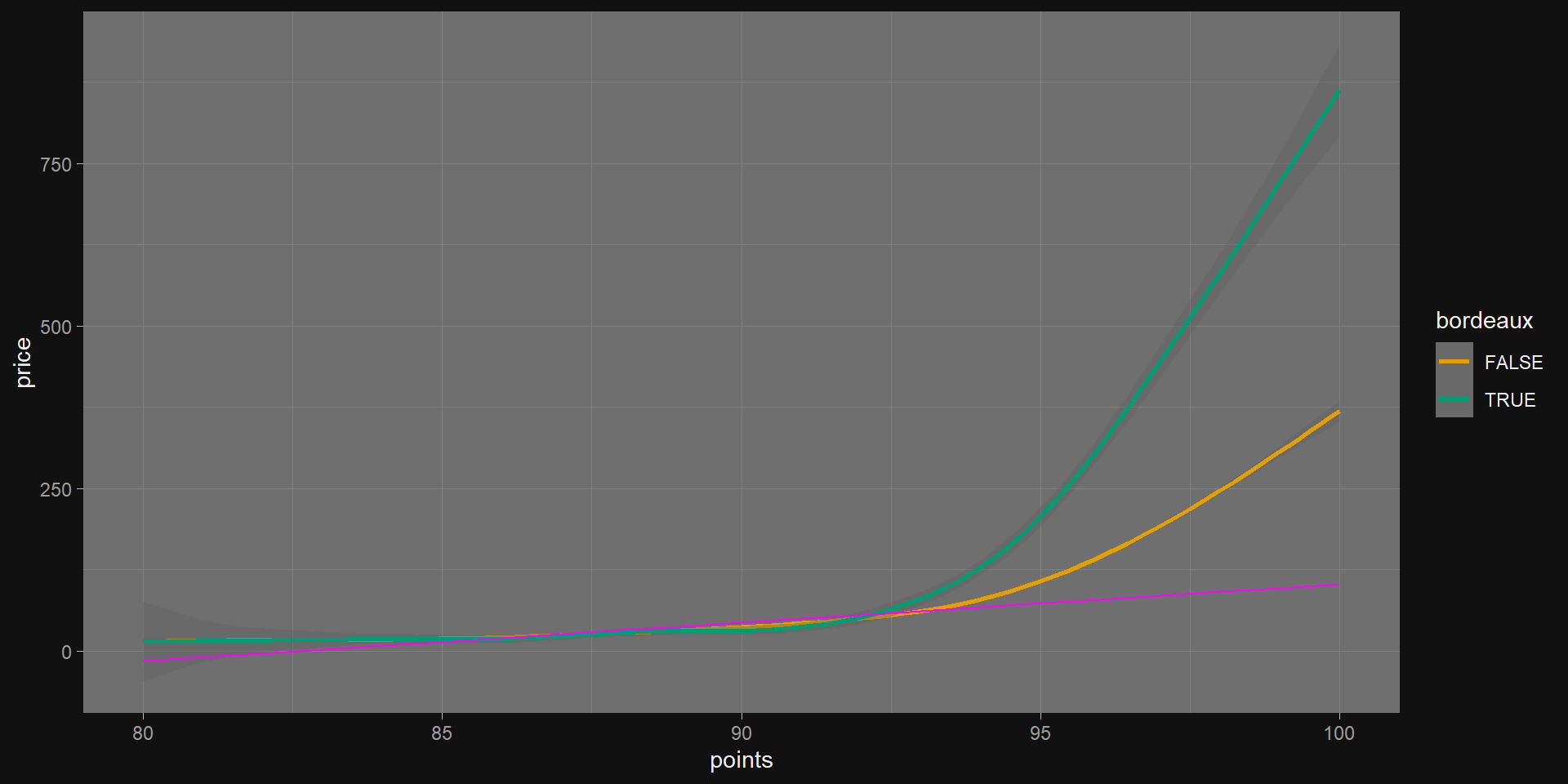
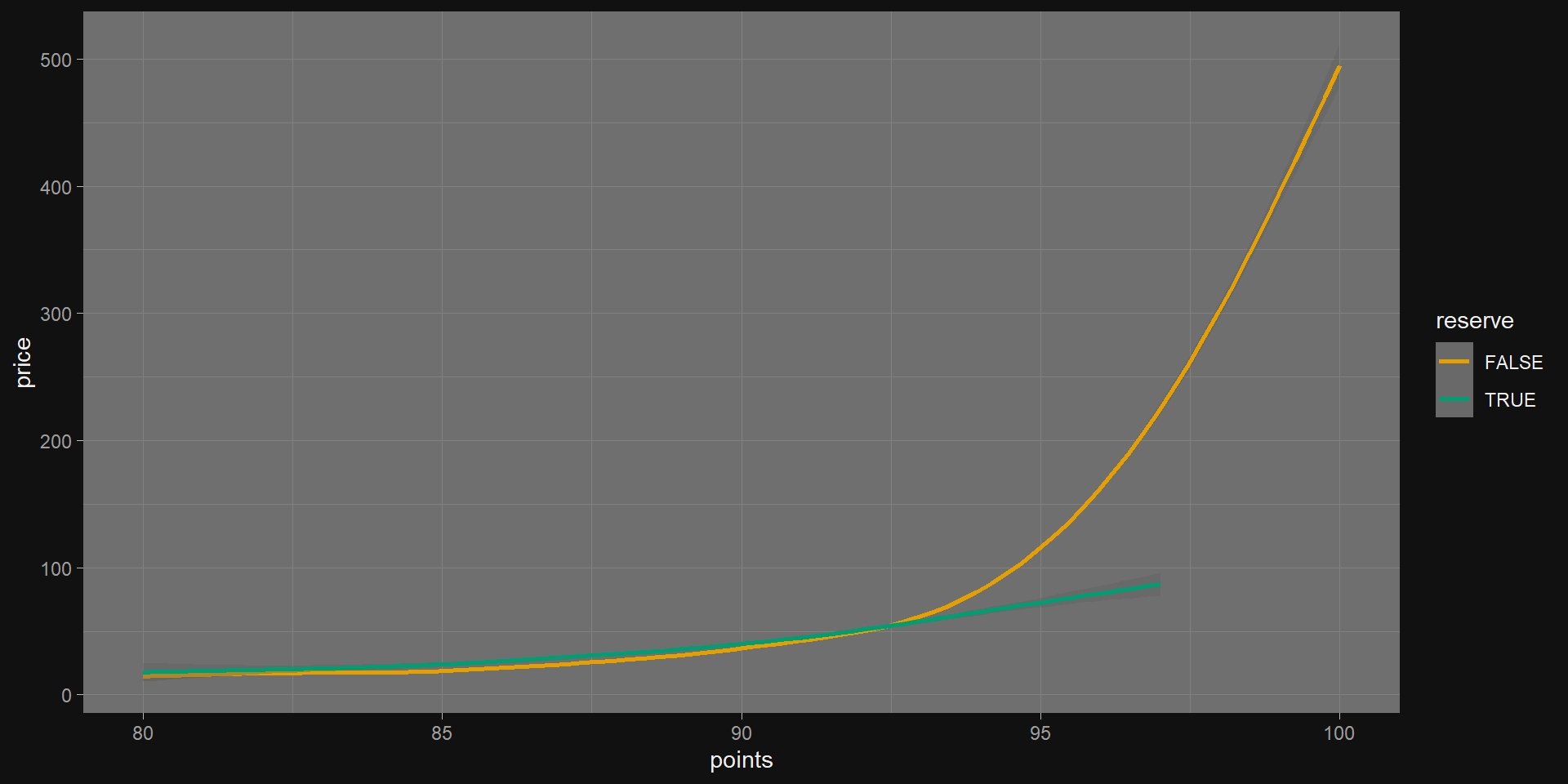
m1 <-lm(price ~ points, data = wine)get_regression_table(m1)
set.seed(505)train_index <-createDataPartition(wine$price, times =1, p =0.8, list =FALSE)train <- wine[train_index, ]test <- wine[-train_index, ]head(test)
# A tibble: 6 × 16
id country description designation points price province region_1 region_2
<dbl> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr>
1 8 Germany Savory drie… Shine 87 12 Rheinhe… <NA> <NA>
2 19 US Red fruit a… <NA> 87 32 Virginia Virginia <NA>
3 20 US Ripe aromas… Vin de Mai… 87 23 Virginia Virginia <NA>
4 28 Italy Aromas sugg… Mascaria B… 87 17 Sicily … Cerasuo… <NA>
5 59 US Aromas of c… <NA> 86 55 Washing… Columbi… Columbi…
6 61 Italy This densel… Prugneto 86 17 Central… Romagna <NA>
# ℹ 7 more variables: taster_name <chr>, taster_twitter_handle <chr>,
# title <chr>, variety <chr>, winery <chr>, year <dbl>, bordeaux <lgl>
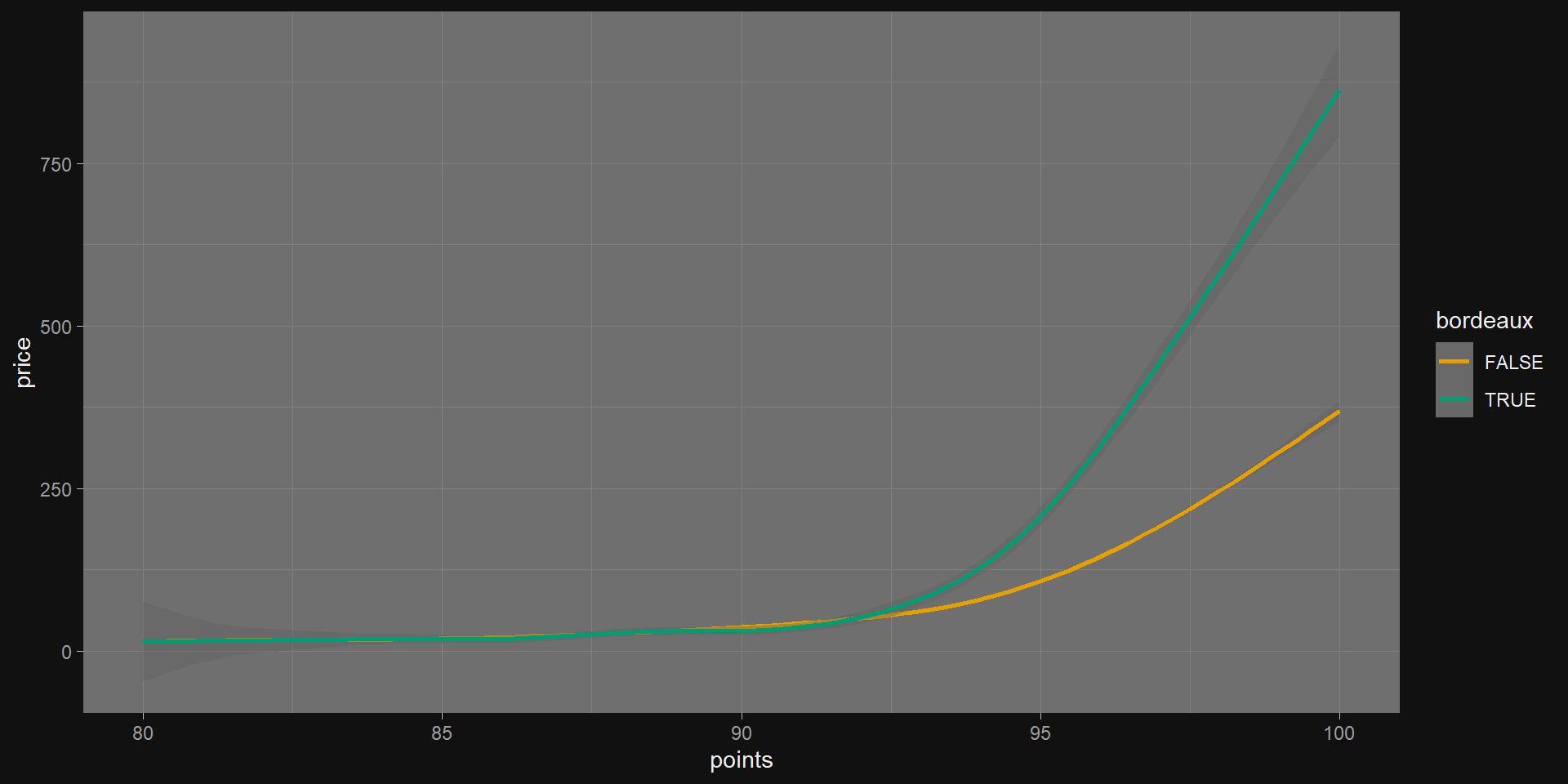
Compare RMSE across models
Retrain on models on the training set
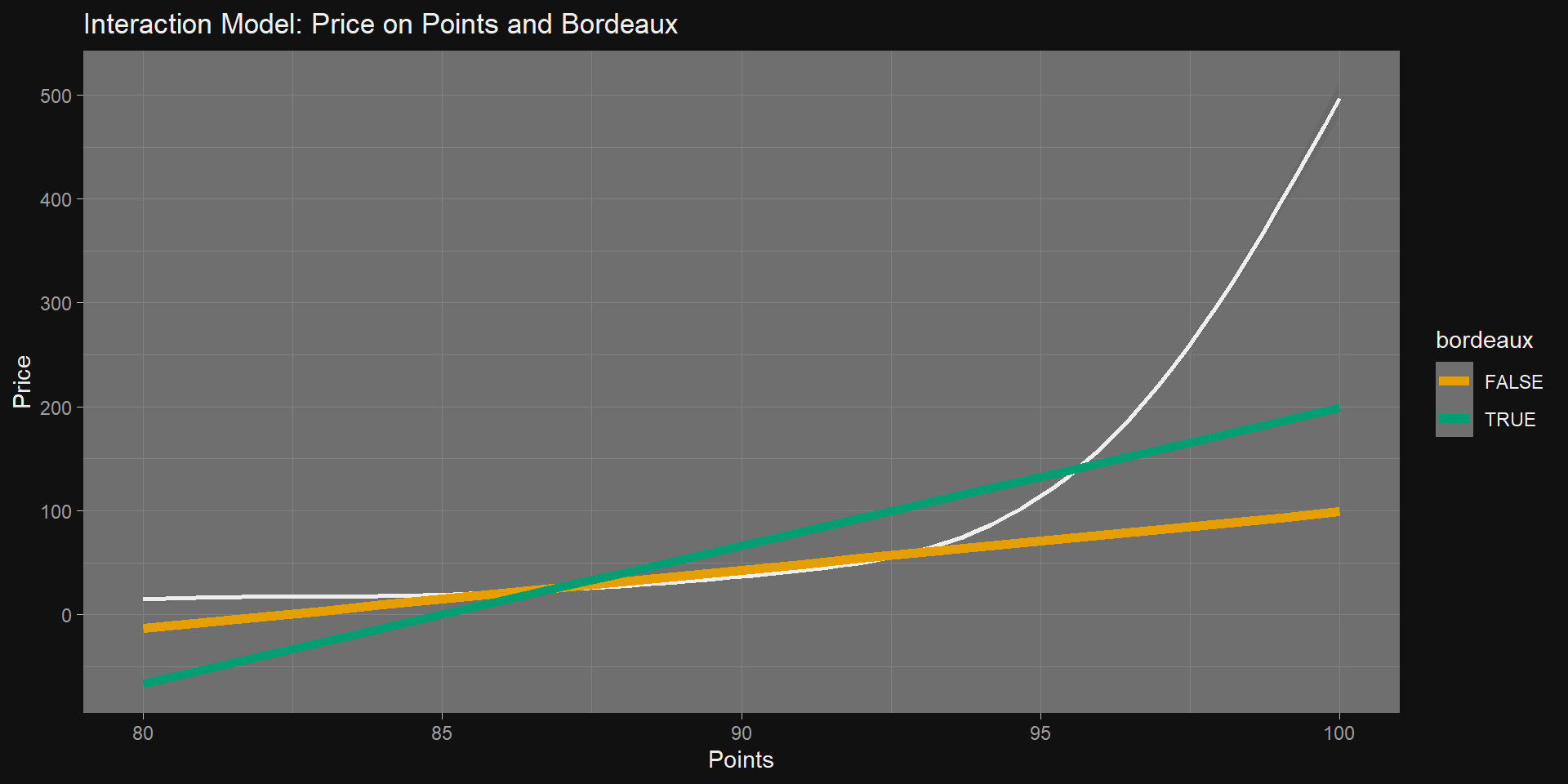
ms <-list(lm(price ~ points, data = train),lm(price ~ points + bordeaux, data = train),lm(price ~ points * bordeaux, data = train))
Reasonable people will disagree over subtle matters of right and wrong… thus, the important part of data ethics is committing to consider the ethical consequences of your choices.
The difference between “regular” ethics and data ethics is that algorithms scale really easily. Thus, seemingly small decisions can have wide-ranging impact.
Calvin on Ethics
No ethical [computation] under capitalism
Usage of data | computing is ethicial iff it challenges rather than strengthens existing power relations.
Vocabulary
ML Terms
Definition of ML: using data to find a function that minimizes prediction error.
Features
Variables
Outcome variable
Regression
RMSE
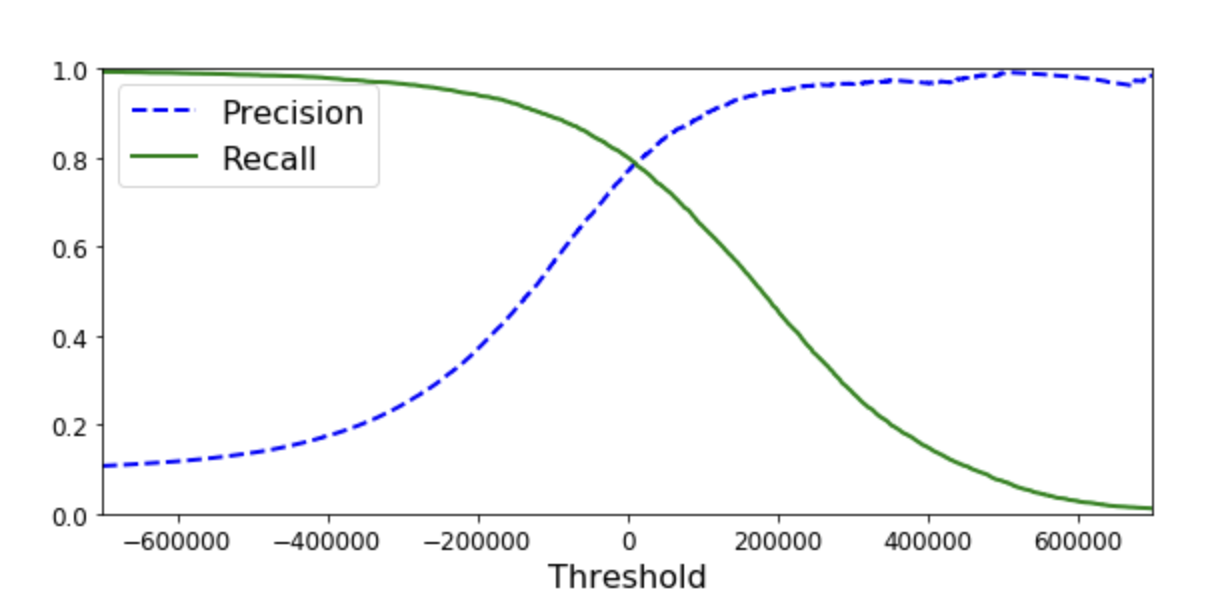
Classification
Confusion matrix
Split Samples
Features
Definition: Individual measurable properties or attributes of data.
Example: Age, income, and education level in a dataset predicting loan approval.
Variables
Definition: Data points that can change and impact predictions.
Example: Independent variables like weather, and dependent variables like crop yield.
Outcome Variable
Definition: The target or dependent variable the model predicts.
Example: Predicting “passed” or “failed” for a student’s exam result.
Features vs. Variables
Features: Inputs to the model, often selected or engineered from raw data.
Example: “Average monthly income” derived from raw transaction data.
Variables: Broader term encompassing both inputs (independent) and outputs (dependent).
Example: “House price” (dependent variable) depends on features like size and location.
Regression
Definition: Statistical method to model the relationship between variables.
Example: Linear regression predicts house prices based on size and location.
RMSE (Root Mean Square Error)
Definition: A metric to measure prediction accuracy by averaging squared errors.
Example: Lower RMSE in predicting drug response indicates a better model fit.
Classification
Definition: Task of predicting discrete categories or labels.
Example: Classifying emails as “spam” or “not spam.”
Confusion Matrix
Definition: A table showing model performance in classification tasks.
Example: Matrix rows show true values; columns show predicted outcomes.
Split Samples
Definition: Dividing data into training and testing subsets for validation.
Example: 80% training, 20% testing ensures unbiased model evaluation.