sh <- suppressPackageStartupMessages
sh(library(tidyverse))
sh(library(tidytext))
sh(library(caret))
sh(library(topicmodels)) # new?
data(stop_words)
sh(library(thematic))
theme_set(theme_dark())
thematic_rmd(bg = "#111", fg = "#eee", accent = "#eee")
wine <- readRDS(gzcon(url("https://cd-public.github.io/D505/dat/variety.rds"))) %>% rowid_to_column("id")
bank <- readRDS(gzcon(url("https://cd-public.github.io/D505/dat/BankChurners.rds")))Dimensionality Reduction
Applied Machine Learning
Visualize

PCA of a multivariate Gaussian distribution centered at (1,3) with a standard deviation of 3 in roughly the (0.866, 0.5) direction and of 1 in the orthogonal direction. The vectors shown are the eigenvectors of the covariance matrix scaled by the square root of the corresponding eigenvalue, and shifted so their tails are at the mean.


Rotation of orthogonal axes
PCA of a multivariate Gaussian distribution centered at (1,3) with a standard deviation of 3 in roughly the (0.866, 0.5) direction and of 1 in the orthogonal direction. The vectors shown are the eigenvectors of the covariance matrix scaled by the square root of the corresponding eigenvalue, and shifted so their tails are at the mean.
Singular value decomposition

Illustration of the singular value decomposition \(U\Sigma V⁎\) of matrix \(M\).
- Top: The action of \(M\), indicated by its effect on the unit disc \(D\) and the two canonical unit vectors \(e_1\) and \(e_2\).
- Left: The action of \(V⁎\), a rotation, on \(D\), \(e_1\) and \(e_2\).
- Bottom: The action of \(\Sigma\), a scaling by the singular values \(\sigma_1\) horizontally and \(\sigma_1\) vertically.
- Right: The action of \(U\), another rotation.
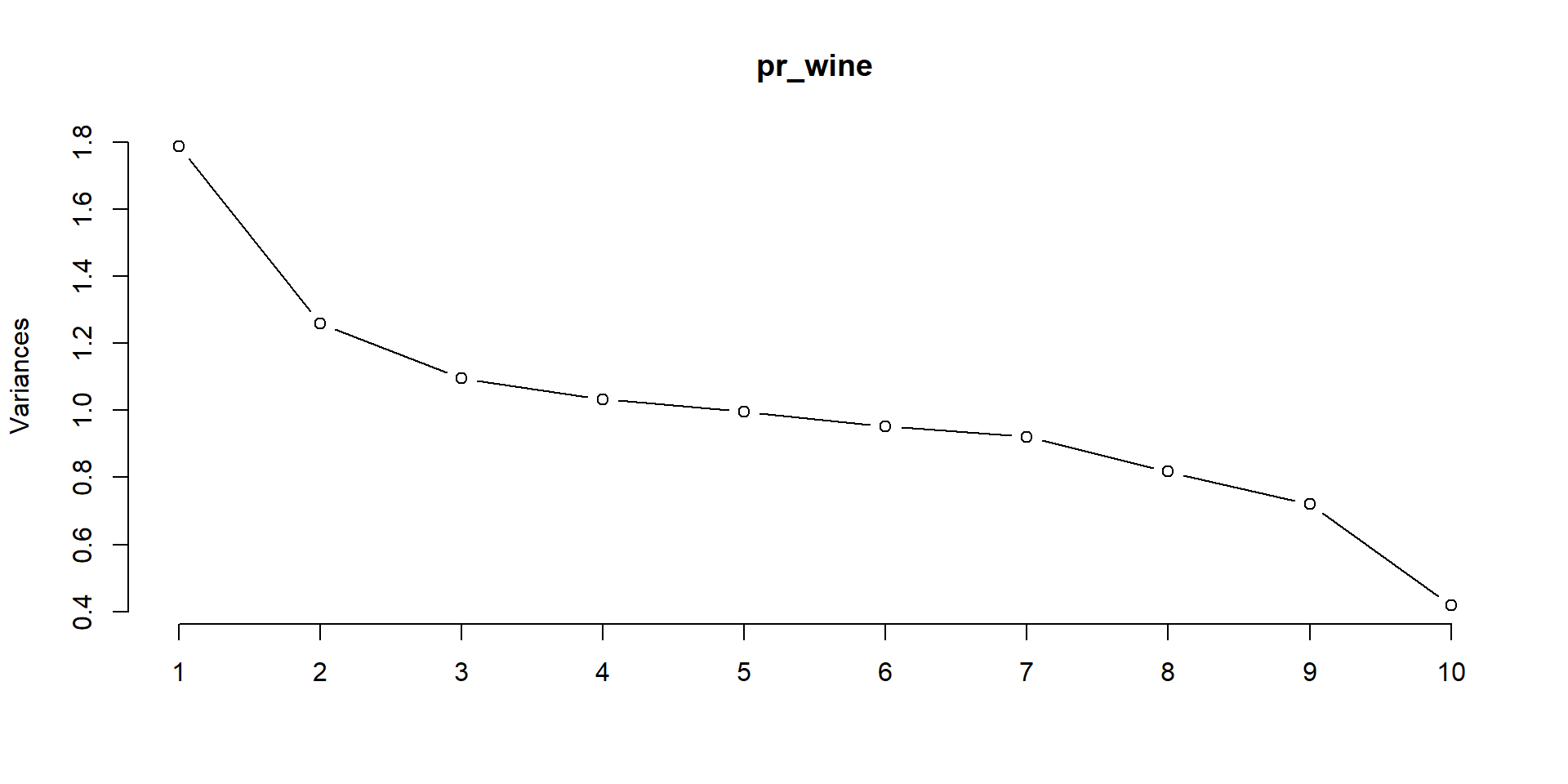
Show variance plot
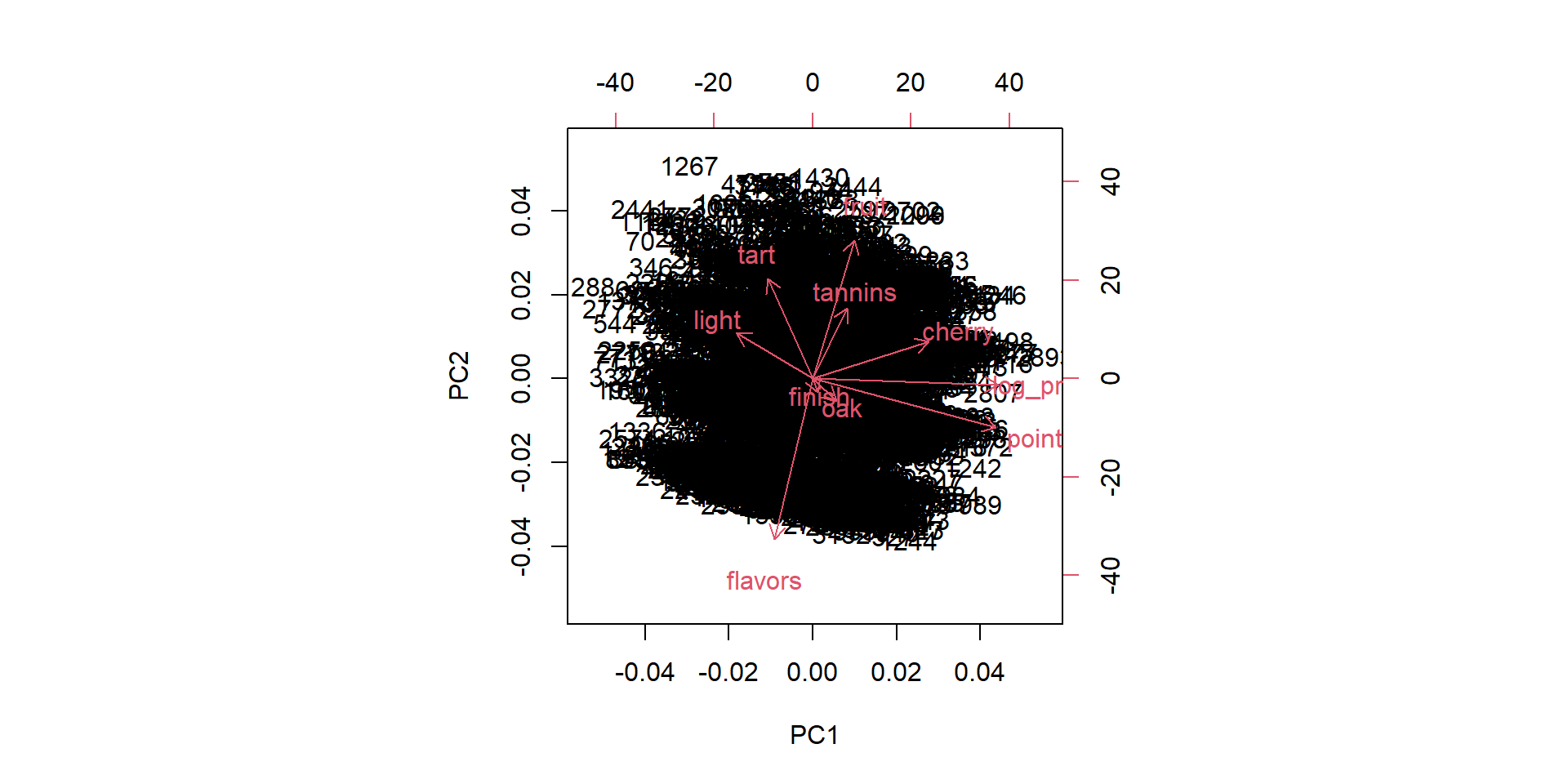
Visualize biplots
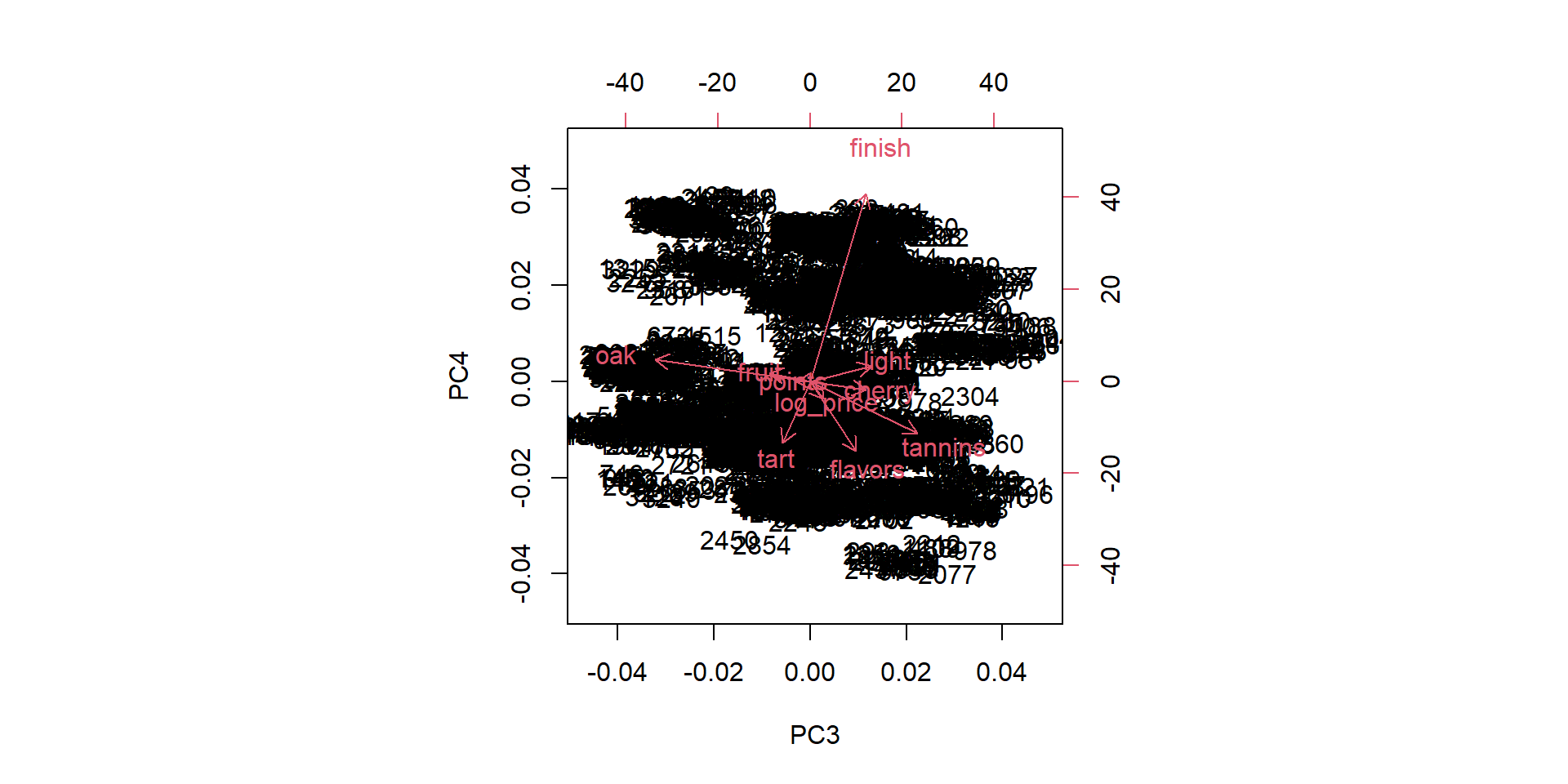
Visualize biplots
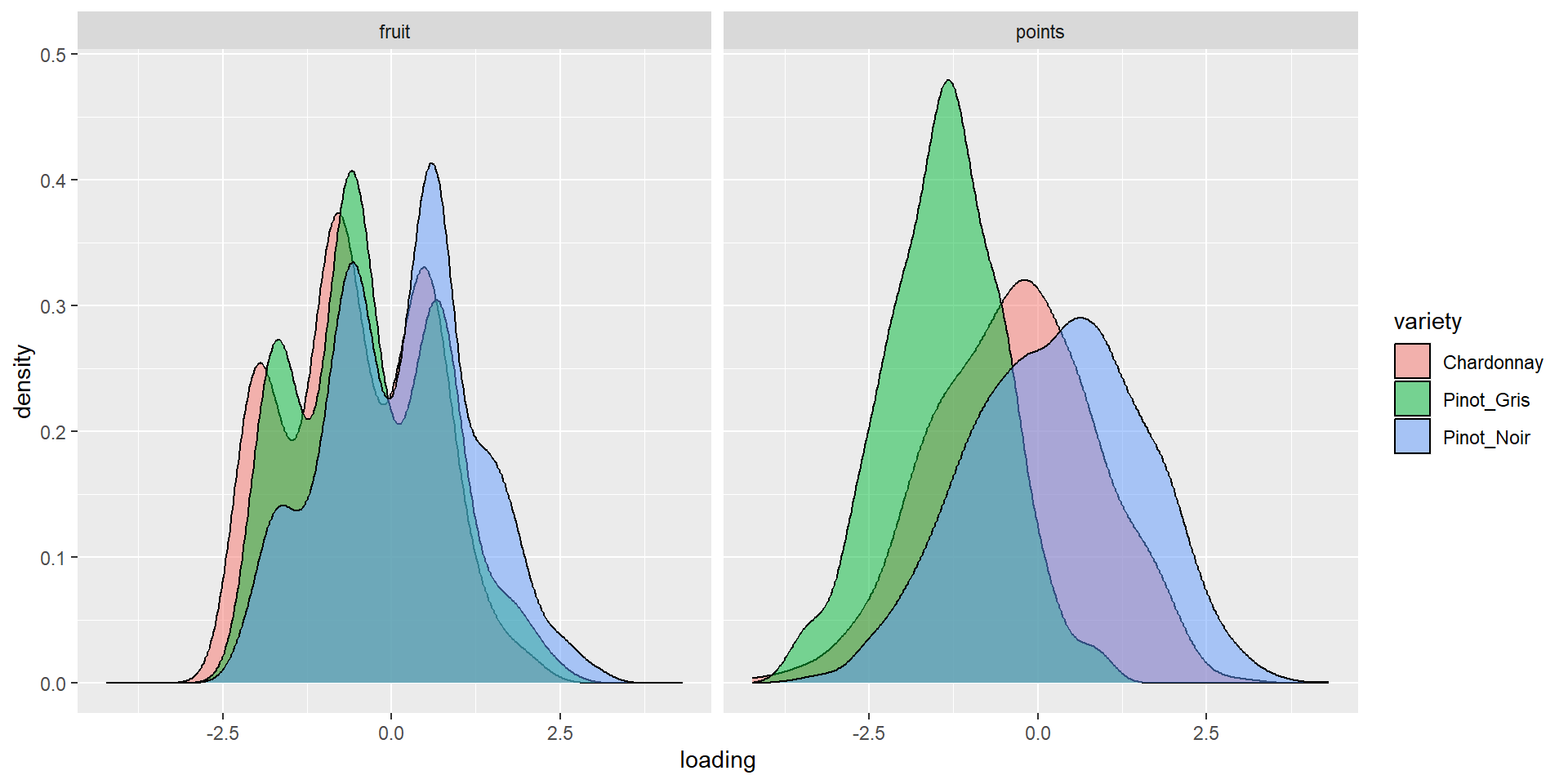
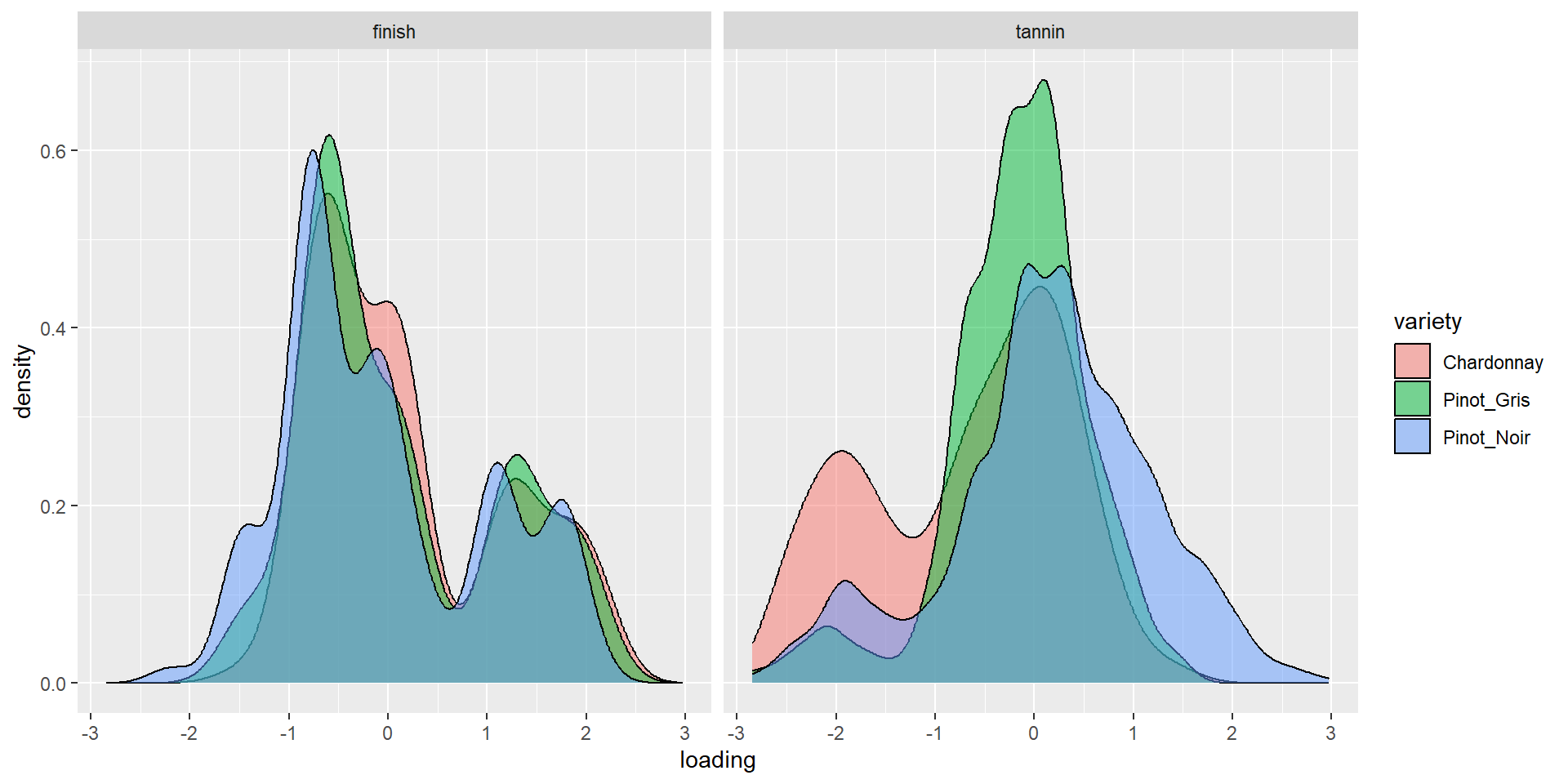
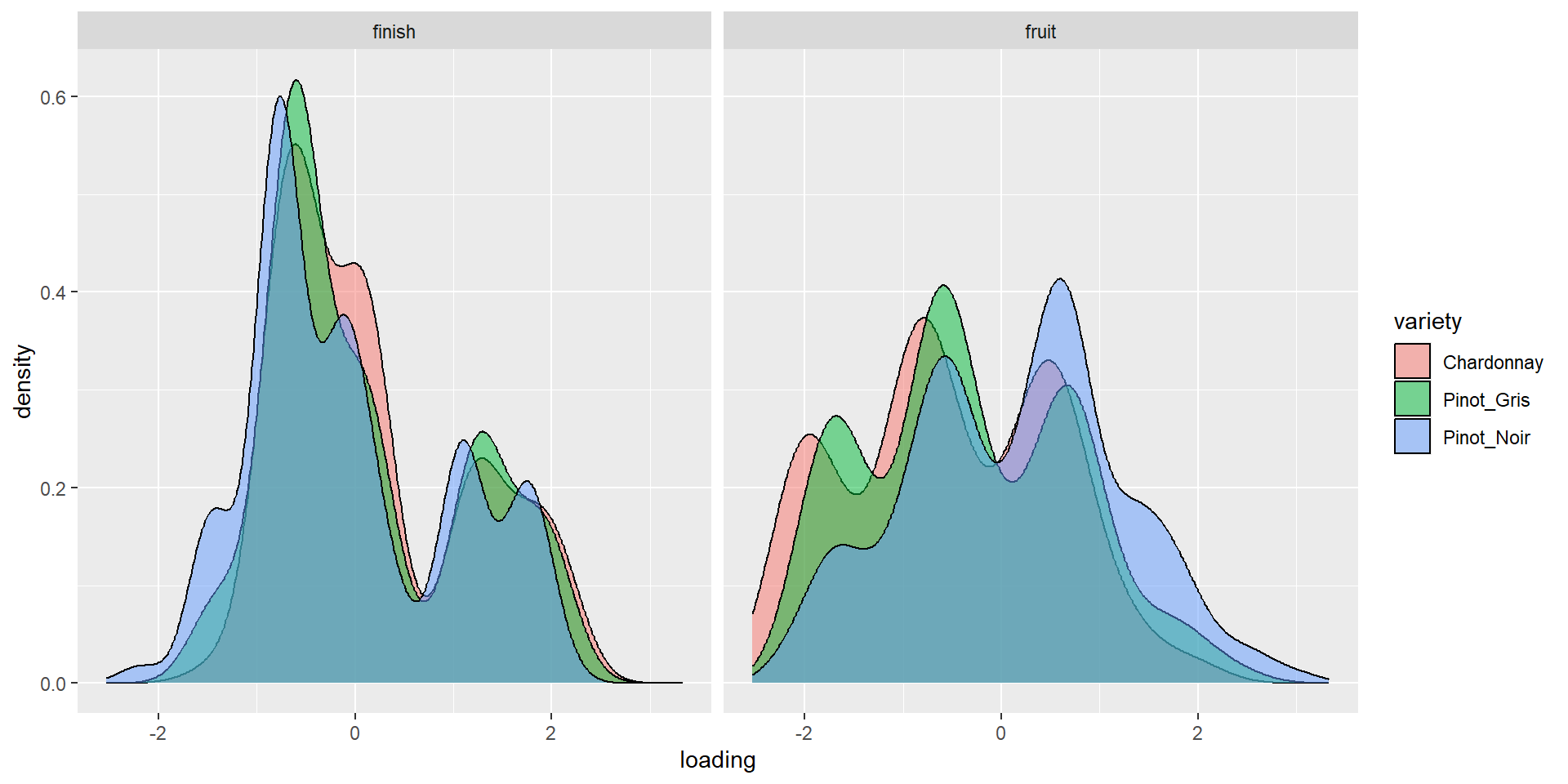
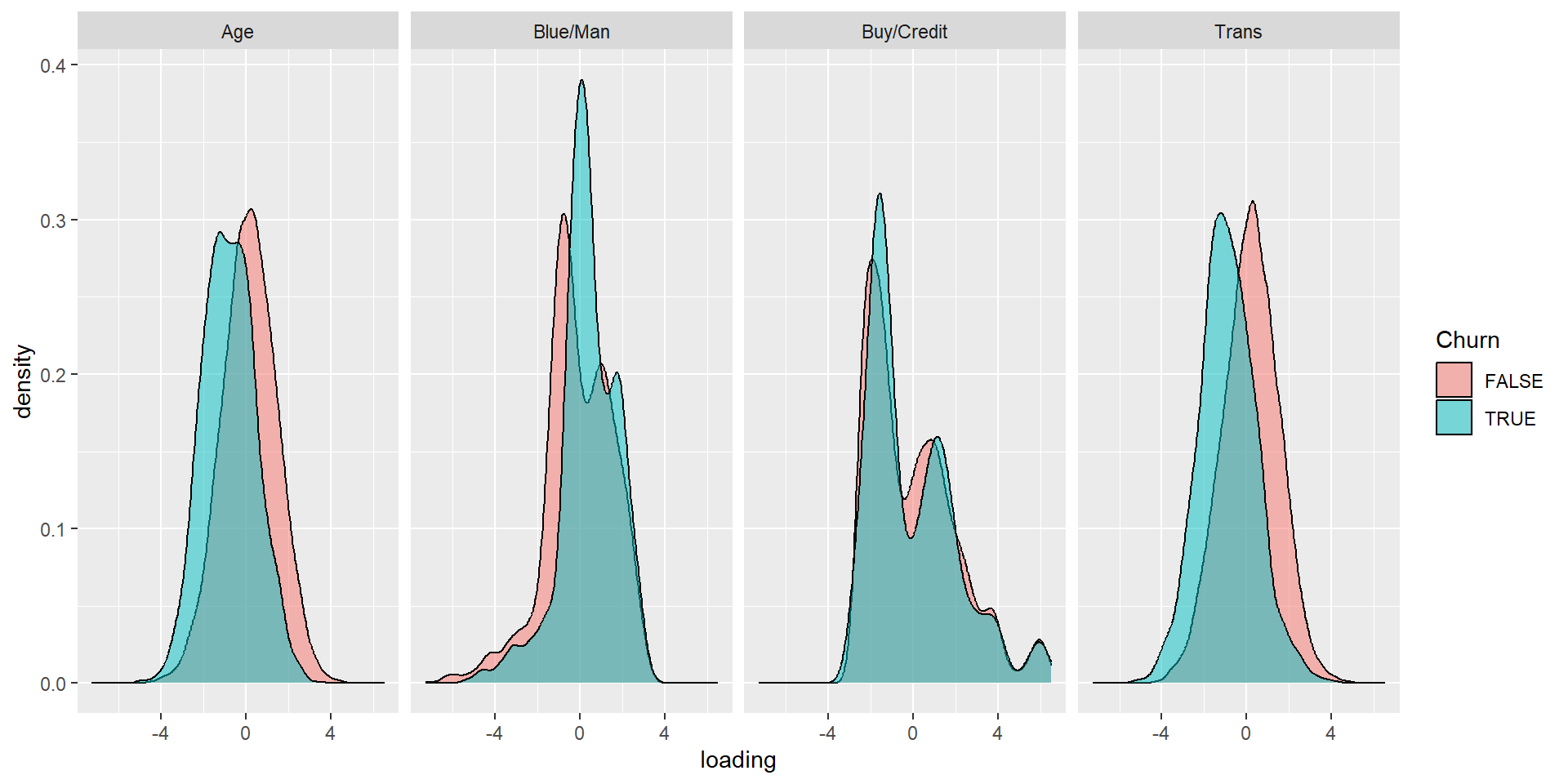
Density by variety (1&2)
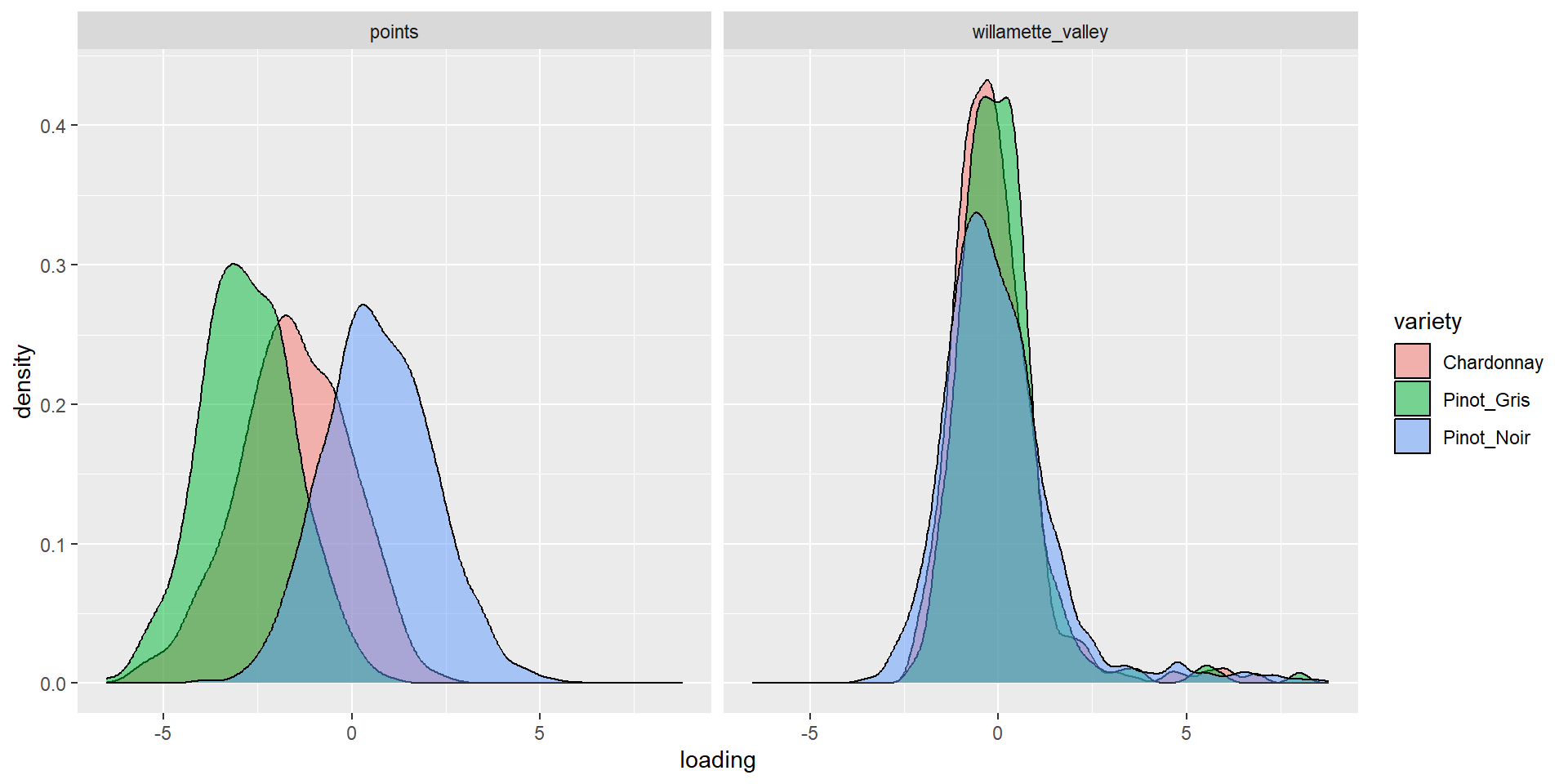
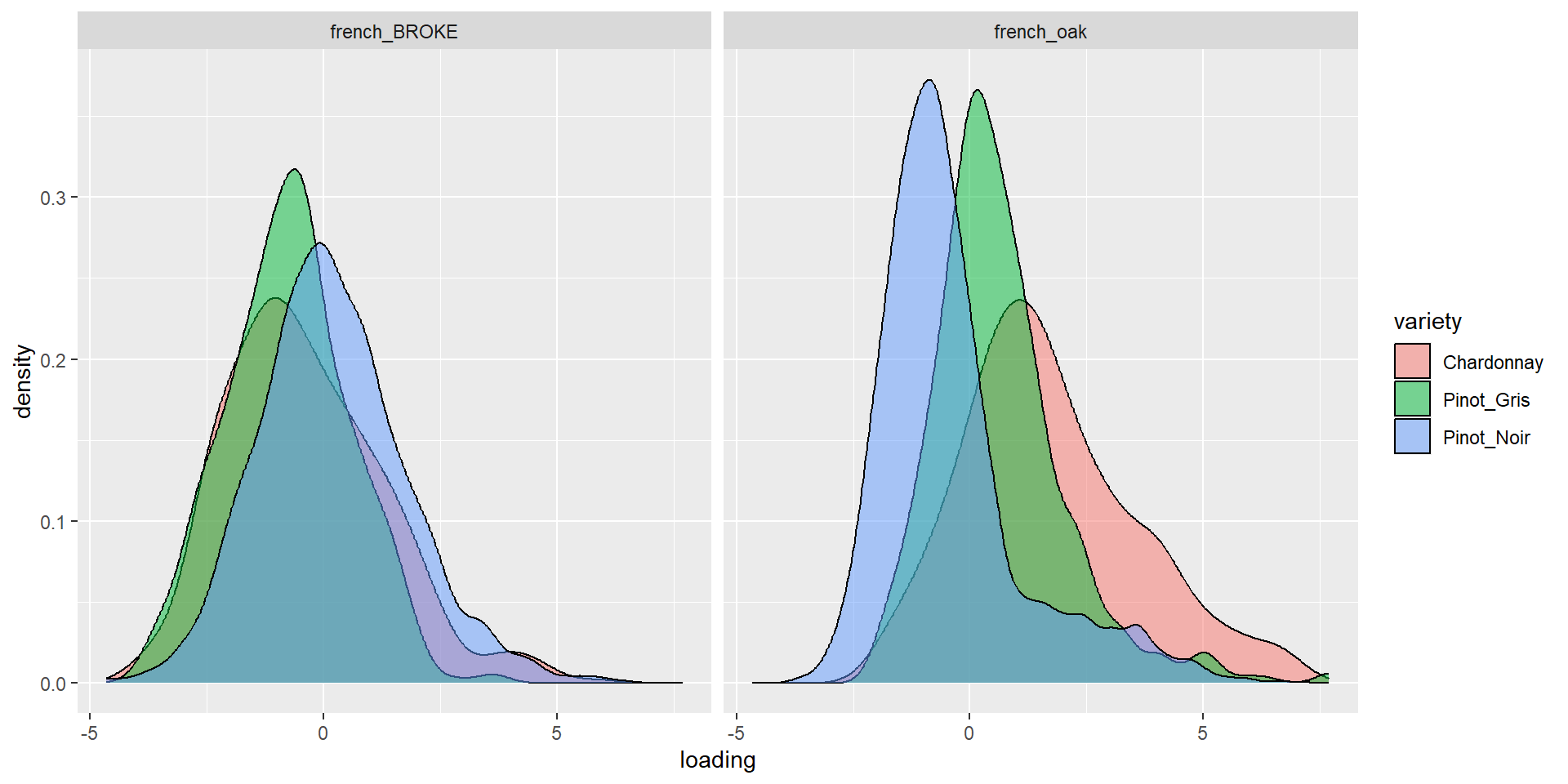
Density by variety (3&4)
Use it
Run PCA

Graph it
Graph more
Hendrik’s solution…
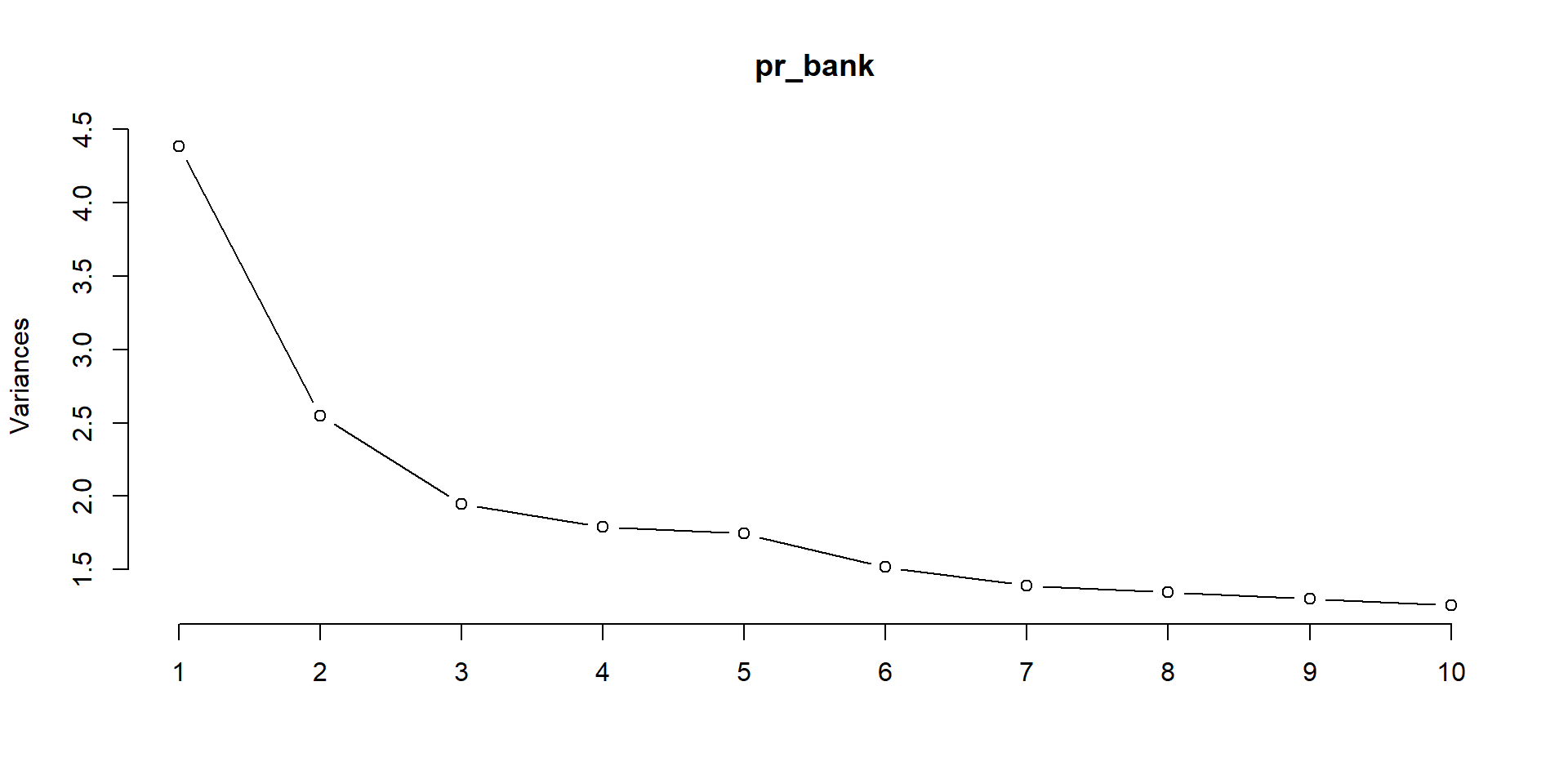
Hendrik’s solution…
Topic Modeling
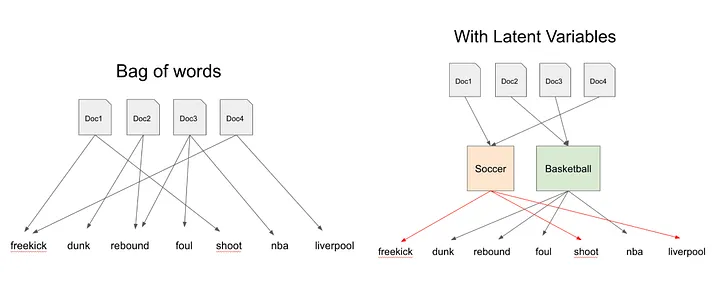
Word-topic probabilities

Top words by topic

Greatest beta differences
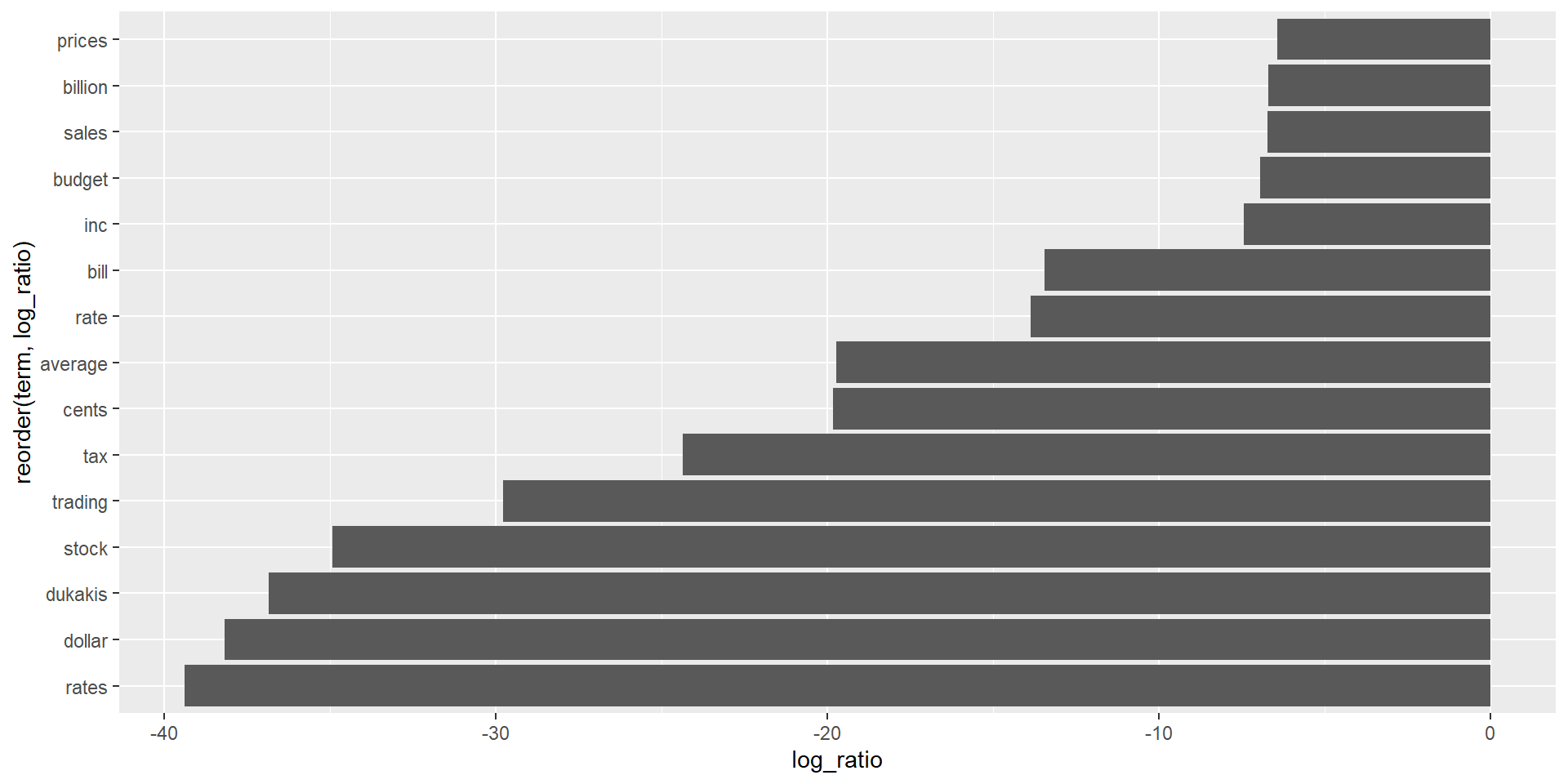
Greatest beta differences
