"What do you do if you code breaks?"¶
This.
factbook = """ American Ethnic Studies 6
Anthropology 2 2 2
Applied Mathematics 2
Archaeology 2 4 3 3 2 10 12 3
Art 1 10 1 5 6 2 21 23 27
Art History 2 1 2 1 1 2 5 7 16
Biology 1 2 6 12 11 12 6 9 24 35 59 28
Business Adminstration 1 4 3 8 6 6 3 18 13 31 18
Chemistry 5 8 3 12 9 5 17 25 42 28
Civic Communication and Media 7 4 9 4 4 8 20 28 6
Classical Studies 2 1 1 1 3 4 11
Computer Science 1 8 1 13 5 8 5 29 12 41 5
Data Science 11 6 10 7 3 4 24 17 41 13
Economics 7 3 15 6 11 7 33 16 49 11
English 1 2 17 4 10 5 9 11 37 48 10
Environmental Science 2 2 14 7 13 2 17 13 44 57 14
Exercise Science 1 2 3 9 8 6 9 11 21 28 49
Film Studies 1 1 2 1 2 3 4 7 5
Global Cultural Studies 1 2 9 5 8 8 17 25 43
History 5 4 6 6 7 5 18 15 33 10
Humanities 1 1 1 1 2
International Studies 3 2 1 4 1 3 5 9 14
Japanese 9
Japanese Studies 4 5 2 5 3 2 9 12 21 2
Mathematics 1 2 3 6 5 4 14 7 21 11
Music 1 3 5 3 1 4 9 13 12
Philosophy 4 3 4 4 2 2 10 9 19 8
Physics 3 8 2 8 2 19 4 23
Politics 4 12 4 13 12 15 20 40 60 7
Psychology 1 3 6 25 4 15 5 15 16 58 74 21
Public Health 8 3 12 2 8 5 28 33 13
Religious Studies 1 1 1 1 2 1
Sociology 2 6 9 1 7 3 22 25 11
Spanish 1 3 2 3 5 6 8 14 23
Special 1 1 1
Statistics 1
Sustianability and Society 6
Symbol Criticism/Rhet Analysis
Theatre 6 3 2 6 2 15 17 5
Women's and Gender Studies 4 4 4 12 """
Let's make a list of majors with at least one student and the inmajor Woman%. While doing this, we will definitely not think at all about gender lest the abyss begin to stare back at us...
majors = [[major[0], major[4], int(major[2]/major[4] * 100)] for major in [[line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]] for line in factbook.split('\n')] if major[4] != 0] # if i ever write one of these in two lines instead of one i get fired
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-2-671e1b1d1cd9> in <cell line: 1>() ----> 1 majors = [[major[0], major[4], int(major[2]/major[4] * 100)] for major in [[line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]] for line in factbook.split('\n')] if major[4] != 0] # if i ever write one of these in two lines instead of one i get fired <ipython-input-2-671e1b1d1cd9> in <listcomp>(.0) ----> 1 majors = [[major[0], major[4], int(major[2]/major[4] * 100)] for major in [[line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]] for line in factbook.split('\n')] if major[4] != 0] # if i ever write one of these in two lines instead of one i get fired IndexError: list index out of range
This code broke in class on 9/23. I'm not sure why; it's not a big deal.
It's composed of inner and outer loop comprehensions, so copy the original and trim down to an inner comprehension. I aim to test about half of the code.
[line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]]
--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-3-34c47c929e3a> in <cell line: 1>() ----> 1 [line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]] NameError: name 'line' is not defined
This looks like it might work but I don't have a line to test on. I'll make one quickly.
line = factbook.split('\n')[0] # split on "enter" and take one element - a single line (the first one, in this case)
[line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]]
['American Ethnic Studies', 0, 0, 0, 0]
Okay that works so the issue is in the outer comprehension. I'll take my processed line and use it in the outer comprehension.
proced = [line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]]
majors = [[major[0], major[4], int(major[2]/major[4] * 100)] for major in [proced] for line in factbook.split('\n') if major[4] != 0] # if i ever write one of these in two lines instead of one i get fired
Okay that seems to have worked. Let's try a few other lines. We'll make functions to simplify testing.
inner = lambda line : [line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]]
[inner(line) for line in factbook.split('\n')]
[['American Ethnic Studies', 0, 0, 0, 0], ['Anthropology', 0, 2, 0, 2], ['Applied Mathematics', 0, 0, 0, 0], ['Archaeology', 2, 10, 0, 12], ['Art', 2, 21, 0, 23], ['Art History', 2, 5, 0, 7], ['Biology', 24, 35, 0, 59], ['Business Adminstration', 18, 13, 0, 31], ['Chemistry', 17, 25, 0, 42], ['Civic Communication and Media', 8, 20, 0, 28], ['Classical Studies', 1, 3, 0, 4], ['Computer Science', 29, 12, 0, 41], ['Data Science', 24, 17, 0, 41], ['Economics', 33, 16, 0, 49], ['English', 11, 37, 0, 48], ['Environmental Science', 13, 44, 0, 57], ['Exercise Science', 21, 28, 0, 49], ['Film Studies', 3, 4, 0, 7], ['Global Cultural Studies', 8, 17, 0, 25], ['History', 18, 15, 0, 33], ['Humanities', 1, 1, 0, 2], ['International Studies', 5, 9, 0, 14], ['Japanese', 0, 0, 0, 0], ['Japanese Studies', 9, 12, 0, 21], ['Mathematics', 14, 7, 0, 21], ['Music', 4, 9, 0, 13], ['Philosophy', 10, 9, 0, 19], ['Physics', 19, 4, 0, 23], ['Politics', 20, 40, 0, 60], ['Psychology', 16, 58, 0, 74], ['Public Health', 5, 28, 0, 33], ['Religious Studies', 1, 1, 0, 2], ['Sociology', 3, 22, 0, 25], ['Spanish', 6, 8, 0, 14], ['Special', 0, 1, 0, 1], ['Statistics', 0, 0, 0, 0], ['Sustianability and Society', 0, 0, 0, 0], ['Symbol Criticism/Rhet Analysis'], ['Theatre', 2, 15, 0, 17], ["Women's and Gender Studies", 0, 4, 0, 4]]
majors = [inner(line) for line in factbook.split('\n')]
outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if major[4] != 0]
outer(majors[0:2])
[['Anthropology', 2, 100]]
Well it's working on a subset. Let's test on the whole thing.
outer(majors)
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-30-dc1890a5b2b6> in <cell line: 1>() ----> 1 outer(majors) <ipython-input-25-75ac97c08368> in <lambda>(majors) ----> 1 outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if major[4] != 0] <ipython-input-25-75ac97c08368> in <listcomp>(.0) ----> 1 outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if major[4] != 0] IndexError: list index out of range
Aha - the same error. We can figure out which line now though.
outer(majors[:len(majors)//2])
[['Anthropology', 2, 100], ['Archaeology', 12, 83], ['Art', 23, 91], ['Art History', 7, 71], ['Biology', 59, 59], ['Business Adminstration', 31, 41], ['Chemistry', 42, 59], ['Civic Communication and Media', 28, 71], ['Classical Studies', 4, 75], ['Computer Science', 41, 29], ['Data Science', 41, 41], ['Economics', 49, 32], ['English', 48, 77], ['Environmental Science', 57, 77], ['Exercise Science', 49, 57], ['Film Studies', 7, 57], ['Global Cultural Studies', 25, 68], ['History', 33, 45]]
outer(majors[len(majors)//2:])
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-32-04fd6932ddc5> in <cell line: 1>() ----> 1 outer(majors[len(majors)//2:]) <ipython-input-25-75ac97c08368> in <lambda>(majors) ----> 1 outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if major[4] != 0] <ipython-input-25-75ac97c08368> in <listcomp>(.0) ----> 1 outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if major[4] != 0] IndexError: list index out of range
It's in the second half.
majors[len(majors)//2:]
[['Humanities', 1, 1, 0, 2], ['International Studies', 5, 9, 0, 14], ['Japanese', 0, 0, 0, 0], ['Japanese Studies', 9, 12, 0, 21], ['Mathematics', 14, 7, 0, 21], ['Music', 4, 9, 0, 13], ['Philosophy', 10, 9, 0, 19], ['Physics', 19, 4, 0, 23], ['Politics', 20, 40, 0, 60], ['Psychology', 16, 58, 0, 74], ['Public Health', 5, 28, 0, 33], ['Religious Studies', 1, 1, 0, 2], ['Sociology', 3, 22, 0, 25], ['Spanish', 6, 8, 0, 14], ['Special', 0, 1, 0, 1], ['Statistics', 0, 0, 0, 0], ['Sustianability and Society', 0, 0, 0, 0], ['Symbol Criticism/Rhet Analysis'], ['Theatre', 2, 15, 0, 17], ["Women's and Gender Studies", 0, 4, 0, 4]]
Now I see it. Do you? It's right there at the end.
majors[-3:]
[['Symbol Criticism/Rhet Analysis'], ['Theatre', 2, 15, 0, 17], ["Women's and Gender Studies", 0, 4, 0, 4]]
One of the majors has no integers! I don't know. But it doesn't matter. We simply update "outer" to ignore anything of the incorrect length.
# was outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if major[4] != 0]
# we make sure that there are three things in line - not just one!
outer = lambda majors : [[major[0], major[4], int(major[2]/major[4] * 100)] for major in majors if len(major) == 5 and major[4] != 0]
outer(majors)
[['Anthropology', 2, 100], ['Archaeology', 12, 83], ['Art', 23, 91], ['Art History', 7, 71], ['Biology', 59, 59], ['Business Adminstration', 31, 41], ['Chemistry', 42, 59], ['Civic Communication and Media', 28, 71], ['Classical Studies', 4, 75], ['Computer Science', 41, 29], ['Data Science', 41, 41], ['Economics', 49, 32], ['English', 48, 77], ['Environmental Science', 57, 77], ['Exercise Science', 49, 57], ['Film Studies', 7, 57], ['Global Cultural Studies', 25, 68], ['History', 33, 45], ['Humanities', 2, 50], ['International Studies', 14, 64], ['Japanese Studies', 21, 57], ['Mathematics', 21, 33], ['Music', 13, 69], ['Philosophy', 19, 47], ['Physics', 23, 17], ['Politics', 60, 66], ['Psychology', 74, 78], ['Public Health', 33, 84], ['Religious Studies', 2, 50], ['Sociology', 25, 88], ['Spanish', 14, 57], ['Special', 1, 100], ['Theatre', 17, 88], ["Women's and Gender Studies", 4, 100]]
Optionally recompose the one-line.
majors = [[major[0], major[4], int(major[2]/major[4] * 100)] for major in [[line.split('\t')[1].strip()] +[int(val.strip()) if val.strip() else 0 for val in line.split('\t')[11:15]] for line in factbook.split('\n')] if len(major) == 5 and major[4] != 0] # if i ever write one of these in two lines instead of one i get fired
majors
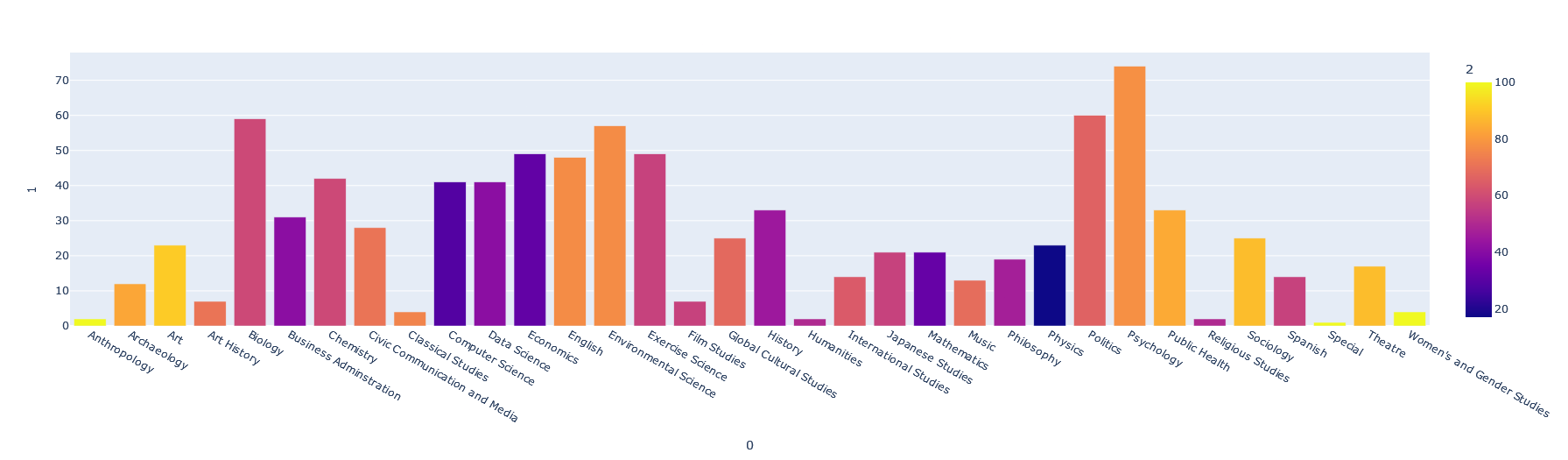
[['Anthropology', 2, 100], ['Archaeology', 12, 83], ['Art', 23, 91], ['Art History', 7, 71], ['Biology', 59, 59], ['Business Adminstration', 31, 41], ['Chemistry', 42, 59], ['Civic Communication and Media', 28, 71], ['Classical Studies', 4, 75], ['Computer Science', 41, 29], ['Data Science', 41, 41], ['Economics', 49, 32], ['English', 48, 77], ['Environmental Science', 57, 77], ['Exercise Science', 49, 57], ['Film Studies', 7, 57], ['Global Cultural Studies', 25, 68], ['History', 33, 45], ['Humanities', 2, 50], ['International Studies', 14, 64], ['Japanese Studies', 21, 57], ['Mathematics', 21, 33], ['Music', 13, 69], ['Philosophy', 19, 47], ['Physics', 23, 17], ['Politics', 60, 66], ['Psychology', 74, 78], ['Public Health', 33, 84], ['Religious Studies', 2, 50], ['Sociology', 25, 88], ['Spanish', 14, 57], ['Special', 1, 100], ['Theatre', 17, 88], ["Women's and Gender Studies", 4, 100]]
import pandas as pd
pd.DataFrame(majors)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | Anthropology | 2 | 100 |
| 1 | Archaeology | 12 | 83 |
| 2 | Art | 23 | 91 |
| 3 | Art History | 7 | 71 |
| 4 | Biology | 59 | 59 |
| 5 | Business Adminstration | 31 | 41 |
| 6 | Chemistry | 42 | 59 |
| 7 | Civic Communication and Media | 28 | 71 |
| 8 | Classical Studies | 4 | 75 |
| 9 | Computer Science | 41 | 29 |
| 10 | Data Science | 41 | 41 |
| 11 | Economics | 49 | 32 |
| 12 | English | 48 | 77 |
| 13 | Environmental Science | 57 | 77 |
| 14 | Exercise Science | 49 | 57 |
| 15 | Film Studies | 7 | 57 |
| 16 | Global Cultural Studies | 25 | 68 |
| 17 | History | 33 | 45 |
| 18 | Humanities | 2 | 50 |
| 19 | International Studies | 14 | 64 |
| 20 | Japanese Studies | 21 | 57 |
| 21 | Mathematics | 21 | 33 |
| 22 | Music | 13 | 69 |
| 23 | Philosophy | 19 | 47 |
| 24 | Physics | 23 | 17 |
| 25 | Politics | 60 | 66 |
| 26 | Psychology | 74 | 78 |
| 27 | Public Health | 33 | 84 |
| 28 | Religious Studies | 2 | 50 |
| 29 | Sociology | 25 | 88 |
| 30 | Spanish | 14 | 57 |
| 31 | Special | 1 | 100 |
| 32 | Theatre | 17 | 88 |
| 33 | Women's and Gender Studies | 4 | 100 |
import plotly.express as px
px.bar(pd.DataFrame(majors),x=0,y=1,color=2)