HDFS
Week 04
Cloud
Announcements
- Welcome to DATA-599: Cloud Computing!
- Python week! (kinda)
- The third homework, "Readme", is due this week at 6 PM on Wed/Thr (now).
- Reviewing these has informed this lecture - I hope that helps!
- Fourth homework is (Actual) WordCount
- Custom Python Hadoop streaming
Today
- Hadoop in Docker in GCP
- This is the incremental step toward fully cloud-centric Hadoop (then Spark!)
- We can now use Hadoop streaming with Python!
- This is good bash/docker practice, and now also GCP practice.
- Hadoop is EASIER but MORE TEDIOUS on cloud
- Everything worked, but...
- Either starting over every session (ew) or using a wide range of cloud services (ew).
- GCP Cloud Console isn't really cloud or really not cloud, it's kinda in between.
- We suffer together 🙏
BIG IDEA
- Cloud computing is complicated, but
- We can break it down into a few "big ideas"
- The first idea: "Data" vs "Compute"
DATA
- How do we use "data" in this context:
- I think of the maximally simple example: assignment
>>> x = 1 - Data is a variable with some value
- These values can be as simple as integers
- These values can be as complex as million-dimension graphs
- I think of the maximally simple example: assignment
- Data is static: it has some fixed value.
- Data is read or written/stored.
- Data is distinct from computation.
Compute
- How do we use "compute" in this context:
- I think of the maximally simple example: incrementation
>>> lambda x: x + 1 - Compute creates data as return values, it may also "consume" data (as arguments)
- These operations can be as simple as incrementation or negation.
- These values can be as complex as climate modelling/protein folding
- I think of the maximally simple example: incrementation
- Compute is dynamic: it is only meaningful relative to some data.
- Compute is "applied" or "defined"
- Compute
iscan be distinct from data.
The Harvard Architecture*
- 'In short [the Harvard architecture] isn't an architecture and didn't derive from work at Harvard'
- A rose by any other name etc.
- That said, "The Harvard architecture is a computer architecture with separate storage and signal pathways for instructions and data."
- Instructions correspond to compute, basically.
- "Do this" vs "Have this"
- We don't often think of Harvard Architectures when we use computers, because modern computers don't act like this*.

*out of scope
A False Dichtomy?
We can think of the Pythonic "functions as values" as a Harvard Architecture violation - storing a compute as data:
>>> y = lambda x: x + 1
And using data as compute:
>>> y(x)
2
Would 'y' live in "instruction memory" or "data memory"? Well...
The von Neumann Architecture
- Also known as the von Neumann model or Princeton architecture
- von Neumann was Jewish-Hungarian huge nerd who worked on the Manhattan Project
- Basically, we can think of instructions (or descriptions of HOW to compute) as data itself.
- Recall: a "Docker image" is a file that describes a "Docker container"
- Recall: a "Docker container" can perform compute operations, like MapReduce.

If we think about inputs and outputs to device, we can imagine inputs as being either data (books) or instructions (wordcount), and outputs being data (wordcounts).
BIG IDEA
- Modern computers, like my laptop, are often thought of as von Neumann machines, with a HDD/SSD holding both data and instructions.
- Cloud computing is composed of modern computers, but doesn't follow the same rules.
- Hadoop uses "compute computers" and "data computers" - it is something of a large-scale Harvard Architecture.
BUT FIRST
- We need to talk about talking about HDFS
- How HDFS/Hadoop work
- Who made HDFS/Hadoop
- "Unfortunate" naming conventions
HDFS
- HDFS is maintained under the Hadoop project and its primary home for documentation is here.
- This documentation is aging, and the ascendent Databricks has a nice page here.
- The Databricks people used to be Hadoop people
- I usually present off of the Databricks documentation, but I use both in practice.
Unfortunate Naming
- Hadoop, HDFS, Spark, and a variety of other open source cloud and web technologies are maintained by an organization called the "Apache Software Foundation" (AFS).
- You will notice I have never said "Apache" or "Apache Software Foundation" in this class...
- That is because, generously, naming a software foundation after an actually existing group of people is weird.
- Quote, Natives in Tech:
It is not uncommon to learn about non-Indigenous entities appropriating Indigenous culture but none of them are as large, prestigious, or well-known as The Apache® Software Foundation is in software circles...
This frankly outdated spaghetti-Western “romantic” presentation of a living and vibrant community as dead and gone in order to build a technology company “for the greater good” is as ignorant as it is offensive.
- Natives in Tech uses "ASF" to refer to the organization when necessary, and I tend to refer to specific technologies by name whenever possible, and use ASF otherwise.
- You can do whatever you want, but this is a weird thing for all of us to have to deal with.
- I'm just sharing what I do.
Unfortunate Naming
- Hadoop/HDFS in particular is oriented around a relationship between what are called "namenodes" and "datanodes".
- It is not uncommon in network programming to have a e.g. a "server" that completes jobs and a "client" that requests jobs, or some other relation.
- HDFS is decribed in this unfortunate way in it's official documentation:
HDFS has a master/slave architecture.
- Unlike ASF, where naming is more tumultous, the tech industry in aggregate has fairly strongly moved away from this terminology for being plausibly offensive and, in fact, pointlessly so - it is not a particularly clear way to describe two computers.
- Among others, Microsoft has a writing style guide that addresses this terminology:
Don't use master/slave. Use primary/replica or alternatives such as primary/secondary, principal/agent, controller/worker, or other appropriate terms depending on the context.
- You do not have to follow a Microsoft style guide but if you don't, you should probably have a good reason not to.
Mains and Secondaries
- In my line of research, I frequently deal with hardware designs implementing standards written prior to the development of more specific terminology, such as the AXI Standard
- With the help of my coauthors, we unambigiously referred to more privileged "main" modules and less privileged "secondary" modules using these terms.
For the ACW signal groups, all registers were helpfully placed into groups by the designer and labeled within the design. The design contained seven distinct labeled groups:...
• ‘S PORT’ - AXI secondary (S) interface ports of the ACW...
• ‘M PORT’ - AXI main (M) interface ports of the ACW...
- This was amicably accepted for publication without elaboration on the meaning of Main/Secondary.
- I was not aware of the Microsoft style guide at the time.
The Harvard Architecture
- I introduced the Harvard Architecture to give another way to think of this:
- We can imagine a "NameNode" as managing all instructions.
- We can imagine a "DataNode" as managing all data memory.
- The "Control unit" is the network they run on, managed by a NameNode
- I/O is usually done on the NameNode
- I/O consists of commands at the commandline, which are ultimately instructions
- In cloud computing, there is no single ALU (or computing unit), rather there are ALUs in every node.
- That is, both memories have one or more attached ALU
An Example
- To see how this terminology can be navigated, we can return to Hadoop vs. Databricks
- Of note, Databricks is not a political organization or affinity group - it is a (very successful) tech start-up making a lot of money doing data science.
- The original Hadoop developers, by contrast, were a decentralized group using consensus-driven decision making and have written some outstanding code but are inherently not in accountability relationships with many groups of people or other organizations.
- They do, in fairness, have a public Diversity and Inclusion statement:
2025 Vision
Become the most equitable open source foundation in the world
- They do, in fairness, have a public Diversity and Inclusion statement:
Hadoop vs Databricks
- Both Hadoop and Databricks documentation describe the HDFS using... the exact same image:
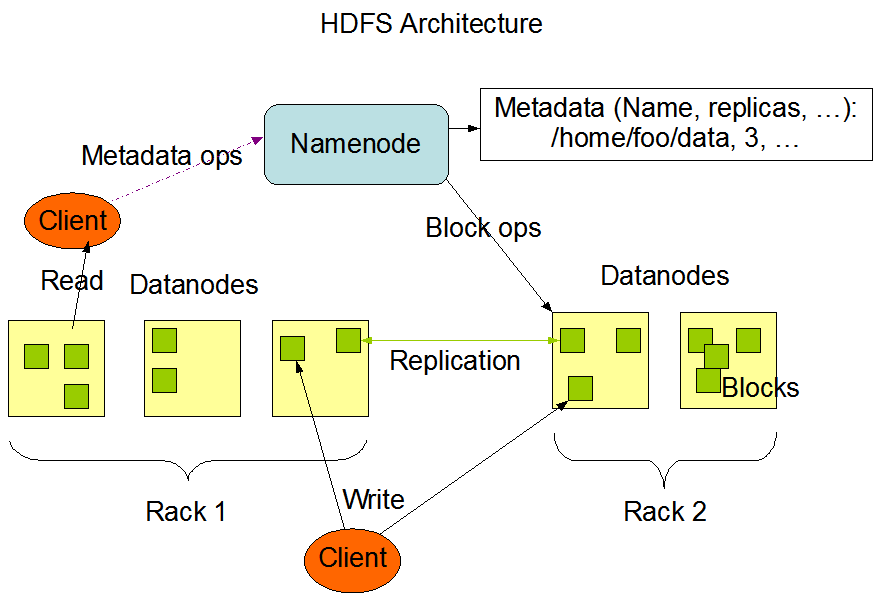
- I think this image is ancient - it was at least used to describing Hadoop v1, which initially released in 2011.
- It's so old, the original uploads are stored as .gif rather than .png files!
- Let's go through line-by-line-ish and understand this architecture and how to talk about it.
Hadoop vs Databricks
- HDFS has a [main/secondary] architecture.
- As we can see, it focuses on NameNodes and DataNodes.
- It is probably easiest to think of NameNodes and DataNodes as their own thing, free from metaphor.
| Hadoop | Databricks | Image |
NameNodes
- An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
- The NameNode is the hardware that contains the GNU/Linux operating system and software.
- The Hadoop distributed file system acts as the master server and can manage the files, control a client's access to files, and overseas file operating processes such as renaming, opening, and closing files.
- The NameNode is by far the closest to how we typically think of a "computer".
- Really only the NameNode "acts" the way we think of computers acting, with its own files and programs and other human-computer interactions.
- Modern Hadoop often has a NodeManager and a NameNode - hence Databricks' cluttered wording.
| Hadoop | Databricks | Image |
DataNodes
- In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on.
- For every node in a HDFS cluster, you will locate a DataNode.
- These nodes help to control the data storage of their system as they can perform operations on the file systems if the client requests, and also create, replicate, and block files when the NameNode instructs.
- I rather more strongly think of the DataNode as a hard disk drive that is very smart.
- In practice, they are in fact entire computers, but we don't think of them the way often think of computers.
| Hadoop | Databricks | Image |
HDFS
- HDFS exposes a file system namespace and allows user data to be stored in files.
- The Hadoop distributed file system acts as the master server and can manage the files, control a client's access to files, and overseas file operating processes such as renaming, opening, and closing files.
- Hadoop states that NameNode can open/close/rename but Databricks says HDFS can open/close/rename.
- In practice, a NameNode is an HDFS - just with a storage size of zero.
- Open/close/rename emerge from the combination of NameNode within an HDFS.
| Hadoop | Databricks | Image |
Commodity Hardware
- In theory, we could run a Hadoop cluster on the computers in this room (true of any room with n>1 computers, including phones)
Hadoop Databricks Image - The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware.
- HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware.
- HDFS operates as a distributed file system designed to run on commodity hardware.
- HDFS is fault-tolerant and designed to be deployed on low-cost, commodity hardware.
- HDFS operates as a distributed file system designed to run on commodity hardware.
- In ~2008, there was more interest in big data than there was dedicated hardware (such as supercomputers like Blue Gene)
- The Hadoop team used consumer electronics to build supercompute capabilities, and...
- There exist open source designs at this scale for a fully open source tech stack. See: CHIPS Alliance.
- Check out what license they operate under!
Use Case
- HDFS provides high throughput access to application data and is suitable for applications that have large data sets.
- HDFS provides high throughput data access to application data and is suitable for applications that have large data sets and enables streaming access to file system data in Apache Hadoop.
- Doing a lot of compute operations per second is cool, but in practice, we care about doing a few operations over a lot of data, in almost all cases.
- If we care about data more than compute, we should care about how data is stored more than how compute is distributed.
- My claim: HDFS and other distributed file systems are the core technology of current tech era.
- My claim: Databricks adds a "streaming" mention because it, and we, are post-Java.
| Hadoop | Databricks | Image |
Blocks
- Once the use case is understood, the core insight of HDFS is "blocks" for data duplication.
Hadoop Databricks Image - Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes
- Next, it's broken down into blocks which are distributed among the multiple DataNodes for storage. To reduce the chances of data loss, blocks are often replicated across nodes.
- Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes
- Basically, a block is a meta-file of fixed size.
- DataNodes hold blocks
- NameNodes keep track of how blocks correspond to files - could be n-to-1, 1-to-n, etc.
- "file name" : "data block" is a key : value pair, where keys (names) are held by the NameNode and values (data blocks) are held by DataNodes
Data Replication
- In 2008, computers were constantly crashing so HDFS was big on "fault tolerance" - one core component was data replication.
Hadoop Image - It stores each file as a sequence of blocks.
- All blocks in a file except the last block are the same size
- Files in HDFS are write-once (except for appends and truncates) and have strictly one writer at any time.
- The NameNode makes all decisions regarding replication of blocks.
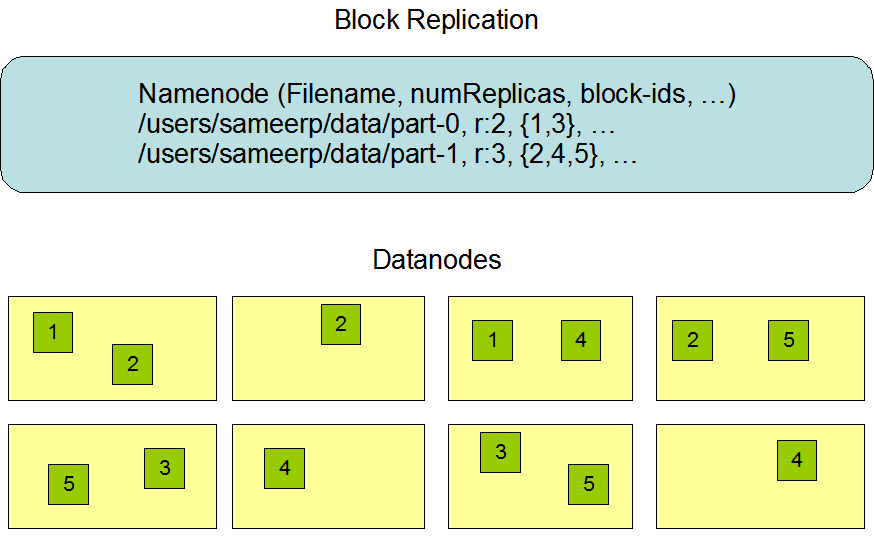
- Did you notice:
- In HDFS, we cannot write a file if there is already a file of that name.
- There is no way to edit internal contents of a file in HDFS.
- Updates are frequently performed with delete + rewrite.
- Container space doesn't go down immediately on delete (e.g. data persists for a bit)
BIG IDEA
- Cloud computing is complicated, but
- We can break it down into a few "big ideas"
- The first idea: "Data" vs "Compute"
A quick note
- I talk about MapReduce, (I think about compute a lot) but Hadoop is more data than compute.
- HDFS is 33 subheadings of Hadoop documentation
- MapReduce is 7
- YARN (a resource monitor that is mostly uninteresting) is 28.

YARN "more like YAWN" is not widely utilized outside of Hadoop, but HDFS and other DFS technologies are.
Streaming
Week 04
Cloud
RECALL: Use Case
- HDFS provides high throughput access to application data and is suitable for applications that have large data sets.
- HDFS provides high throughput data access to application data and is suitable for applications that have large data sets and enables streaming access to file system data in Apache Hadoop.
- Doing a lot of compute operations per second is cool, but in practice, we care about doing a few operations over a lot of data, in almost all cases.
- If we care about data more than compute, we should care about how data is stored more than how compute is distributed.
- My claim: HDFS and other distributed file systems are the core technology of current tech era.
- My claim: Databricks adds a "streaming" mention because it, and we, are post-Java.
| Hadoop | Databricks | Image |
Today
- Hadoop in Docker in GCP
- These is the incremental step toward fully cloud-centric Hadoop (then Spark!)
- We can now use Hadoop streaming with Python!
- This is good bash/docker practice, and now also GCP practice.
- Readme version here.
Google Cloud Shell
- Access a cloud shell:
- https://shell.cloud.google.com/
- I had a transient Cloud Shell outage today but I previously got everything working there.
- These instructions are written targetting Cloud Shell but only verified locally and on Compute Engine.
If Cloud Shell is down, you can make a VM (Compute Engine) and work within it. Running Docker on Compute Engine is awkward (requires sudo) but possible, read this.
Azure and AWS
- These instructions won't work on Azure Cloud Shell.
- Azure Cloud Shell runs inside a container itself. Whoops!
- AWS is still denying my educational license, so I haven't tested there.
A VM on either service should be more than sufficient.
Docker
We set up docker outside of a Hadoop container, such as in Bash, Cloud Shell, or an SSH session with a Compute Engine vm.
Put on your "I'm not inside a container" hat
Verify Docker Presence
- We want to make sure our environment supports docker.
docker run hello-world
Git Hadoop Dockerfiles
- We previously used a number of Hadoop container repositories.
- Today I will be using "Hadoop Sandbox".
- From asking around, it seems more stable than the other Hadop repositories, though it is a bit larger.
git clone https://github.com/hadoop-sandbox/hadoop-sandbox.git cd hadoop-sandbox
Bring Up Hadoop Cluster
- Like always:
docker compose up -d - Once our compose operation is complete, we verify health.
docker ps - After about 5ish minutes, I saw only healthy images.
- I've really come around on using the '-d' flag
- it makes it much easier to know when the cluster is "online" since we get the command prompt back when it is.
- Some confusion I've had came from trying to use clusters that didn't come online or didn't come online yet.
SSH into the Hadoop Cluster
- We use ssh to work in the the cluster.
- This is novel!
- We are not using 'docker exec' here
- It will feel mostly the same, but is more cloud friendly!
- We work as as the "sandbox" user.
- This user is configured to run Hadoop jobs.
ssh -p 2222 sandbox@localhost - The password is "sandbox".
- You will be asked.
- Your typing might not show up - it's there I promise!
- Consult the Hadoop-Sandbox readme for any questions about logging in.
Hadoop Streaming
We perform Hadoop streaming inside a Hadoop container.
Take off your "I'm not inside a container" hat
Put on your "I'm inside a container" hat
Mapred Verification
- The latest distributions of Hadoop support the "mapred streaming" command for Hadoop streaming.
- You can verify that your Hadoop distribution has this with a help command:
mapred streaming --help - If you do not have this command:
- Verify you have some Hadoop distribution
- Find the Hadoop version and the corresponding streaming jar, such as 2.7.3.
Curl Sample Data
- I use the same books as always.
mkdir books curl https://raw.githubusercontent.com/cd-public/books/main/pg1342.txt -o books/austen.txt curl https://raw.githubusercontent.com/cd-public/books/main/pg84.txt -o books/shelley.txt curl https://raw.githubusercontent.com/cd-public/books/main/pg768.txt -o books/bronte.txt ls books - Hadoop is designed to work on 1 TB+ sizes, but that is a lot of books!
- All these books are under a MB (we'd need ~2 mil+ books)
Store Data in HDFS
- The sandbox user (us) only has write permission to /user/sandbox within HDFS.
- This is good (prevents mistakes), but...
- ... potentially annoying (have to type more without typos)
- We create a books directory in HDFS.
hdfs dfs -mkdir /user/sandbox/books - We copy the books in the local books folder to the HDFS books folder.
hdfs dfs -copyFromLocal -f books/* /user/sandbox/books - We can verify (ls, cat, head, etc):
hdfs dfs -ls /user/sandbox/books
Canonical MapRed
- The "hello world" Hadoop Streaming job uses "cat" and "wc".
- This does coun words but not the way WordCount.jar did.
- I've simplified it here, once you get this working take a look at the documentation.
mapred streaming \ -input /user/sandbox/books \ -output /user/sandbox/words \ -mapper cat \ -reducer wc - Read more
- The documentation uses full paths for cat/wc
- This is fraught with peril, but...
- Less likely to trigger 'not found' type errors once debugged.
- The documentation doesn't use literal paths for input/output.
- The documentation uses full paths for cat/wc
Verify Completion
- We confirm that the job was successful by investigating the words folder in HDFS.
hdfs dfs -ls /user/sandbox/words - The output will likely be in part-00000, but check before you read.
hdfs dfs -head /user/sandbox/words/part-00000 - Before and after looking, consider: What do you expect to see?
SIDEBAR: The Pipe '|' Operator
- We are going to talk about Bash for just a moment.
- Still within the context of the Hadoop container, but
- Generally useful information.
SIDEBAR: cat
- 'cat' concatenates a list of files and prints it to command line:
echo "some words" > one.txt echo "other words" > two.txt cat one.txt two.txt - We get:
some words other words
SIDEBAR: wc
- 'wc' counts
- lines,
- words, and
- characters in a file.
wc one.txt
SIDEBAR: wc
- It's helpful to get a sense for wc from managable but non-trival sized files.
- The lyrics to Mark Ronson "Nothing Breaks Like a Heart" feat. Miley Cyrus.
- A four minute pop track at typical speaking tempo.
51 356 1893 nothing.txt- 51 lines (stanzas)
- 356 words
- 1893 characters
- Austen's Pride and Prejudice
- A ~300 page novel in conversational language
14911 130408 772420 austen.txt- 15k lines (stanzas)
- 130k words
- 770k characters
- Project Gutenberg 28 vol. encyclopedia
4112430 37746754 232673172 enc.txt
SIDEBAR: Pipe '|'
- Pipes pass the output of one command to the input of another command.
- We could count words in two files:
cat books/* | wc - This is basically what MapRed streaming is doing - just all at once.
- It is also how one can combine a 28 vol. encyclopedia!
SIDEBAR: Pipes
- MapReduce isn't exactly applying cat and wc and doing nothing else
- Somehow MapRed has some sorting going on in it? Probably hashing?
- But basically, MapRed streaming does this command but on more than one CPU at a time.
cat books/* | wc - I get similar but not identical values for pipe '|' method and and mapred - good enough for now.
SIDEBAR: Process Substitution
- Last wrinkle: the '<' and '>' operators.
- I use this a lot to make little files:
echo "hello world" > hi.txt - In this command, instead of the console capturing command output, it is captured in the file "hi.txt".
- This is a good way to do intermediate steps to pipes using files.
- Here is an advanced command to compare the MapRed and "pipe" variants.
Read more
diff <(cat books/* | wc) <(hdfs dfs -cat /user/sandbox/words/part-00000) - Take a moment to think about what the components mean.
- I use diff a lot! Check it out.
Python Streaming Setup
End Sidebar
- In addition to Java jars and BASH commands, we can also stream with Python scripts.
merrer
I have created a repository with a sample 'mapper.py' and 'reducer.py' files.
These are adapted from a G4G tutorial and translated to Python3.
- Use mine, or...
- Fork and modifying, or...
- Make your own original, or...
- Find someone else's.
You'll need your own someday, but not yet.
Curl Python Scripts
- My container did not have git installed
- It seemed easier to curl than install git or vi or attempt to write Python via echo.
- Github helpfully hosts "raw" data with appropriate file name and extension.
mkdir scripts curl https://raw.githubusercontent.com/cd-public/merrer/main/mapper.py -o scripts/mapper.py curl https://raw.githubusercontent.com/cd-public/merrer/main/reducer.py -o scripts/reducer.py - Next best: Cloud Editor and 'docker cp' in an external shell (that is, not sandbox).
Building the Hadoop command
- Hadoop helpfully has a streaming command example using Python:
- Of note, any files (like .py files) used must also be passed as an additional '-file' parameter.
- This is because Hadoop must copy these scripts to each DataNode.
- The DataNode will use their copy of the (.py) files on data pulled from within HDFS.
- I pre-delete the output directory so I can rerun if I hit errors.
hdfs dfs -rm -r /user/sandbox/words mapred streaming \ -input /user/sandbox/books \ -output /user/sandbox/words \ -mapper mapper.py \ -reducer reducer.py \ -file scripts/mapper.py \ -file scripts/reducer.py - This won't work (yet!) for two reasons but you can run it to see what happens.
- You could save this as an .sh script!
Cluster Python Install
We install Python from outside of the container.
I am taking off my "inside the container" hat.
I am putting on my "outside the container" hat.
Installing Python on a Docker Container
- Much text:
- Of note, we are install on containers, not images, so this install will not persist.
- Containers are actually running imaginary compuers.
- Images are descriptions of how to start running containers.
- When containers shut down, changes to their data and computation are not saved anywhere.
- We cannot install from within our ssh sessions because:
- We are only in one node, and
- We do not have install permissions.
- Takeaway: You have to do all this every time you 'docker compose up -d' unless you change images.
Docker Exec
- We can use 'docker exec' to invoke commands within a container from the host device. For example:
docker exec -it hadoop-sandbox-datanode-1 python3 - Before installing Python on a node, this will probably return an error - and this is the error that prevents us from being able to stream jobs (yet!).
APT
- Not-quite sidebar.
- APT, "advanced package tool", is a common and powerful command-line utility.
- It is present on most containers I've worked with, but...
- Unlikely computers which updates themselves, container images are static, and
- Container APTs are usually not up-to-date.
- To install the latest packages, such as Python 3, it is usually necessary to first "update":
apt-get update - Note: this needs to be done wherever Python is needed - that is, within containers.
- When I install Python, it unhelpfully asks me if I'm sure during the process. I add the '-y' flag to make things easier for me.
apt-get -y install python3
APT on a Container Cluster
So we will create a new command line and install Python via 'docker exec'
- This is a lot of text, but it just (1) updates packages then (2) installs Python on each of the (1) NameNode, (2) DataNode, (3) ClientNode, and (4) NodeManager.
- So 2 * 4 = 8 commands.
- I thought DataNode would be sufficient, and it's possible not all of these are necessary, but this worked for me.
- This could be easily automated if I realized how many containers I'd need to work with in advance.
- Could this be done in a .sh or .py command on a host machine in fewer than 8 lines?
docker exec -it hadoop-sandbox-datanode-1 apt-get update
docker exec -it hadoop-sandbox-datanode-1 apt-get -y install python3
docker exec -it hadoop-sandbox-namenode-1 apt-get update
docker exec -it hadoop-sandbox-namenode-1 apt-get -y install python3
docker exec -it hadoop-sandbox-clientnode-1 apt-get update
docker exec -it hadoop-sandbox-clientnode-1 apt-get -y install python3
docker exec -it hadoop-sandbox-nodemanager-1 apt-get update
docker exec -it hadoop-sandbox-nodemanager-1 apt-get -y install python3
Python Streaming Test
Take off your "I'm not inside a container" hatPut on your "I'm inside a container" hat
chmod
- Before passing a Python file off to a DataNode to be run, I verify it has run permissions.
- We can see if there a 'x' - for executable - by examining permissions using 'ls'.
ls -al scripts - You'll see something like '-rw-r--r--' probably with no x's at first.
- If there aren't x's there, or even if there are and we want to be sure, we set permissions to be maximally permissible with 'chmod'
chmod 777 scripts/mapper.py chmod 777 scripts/reducer.py - Permissions are in octal, so 777 is equal to binary '111111111' which stands for read, write, and execute permissions for 'user', 'group', and 'other.
- This would be represented as 'rwxrwxrwx'
- Each 'rwx' is a 7 or a 111.
- Read more.
chmod
- Emphasis slide.
- chmod is important.
Mapred Stream
- With a Python install and chmod, the following prepared command (hopefully) runs without error:
hdfs dfs -rm -r /user/sandbox/words mapred streaming \ -input /user/sandbox/books \ -output /user/sandbox/words \ -mapper mapper.py \ -reducer reducer.py \ -file scripts/mapper.py \ -file scripts/reducer.py - Once this runs - you've used Python for Big Data.
- Congrats!
View Output
- Output from the example script will be in /user/sandbox/words/, probably as part-00000.
hdfs dfs -ls /user/sandbox/words hdfs dfs -head /user/sandbox/words/part-00000 - We can also copy to the local file system.
hdfs dfs -copyToLocal /user/sandbox/words - And view the output within the words directory:
ls words head words/part-00000
Python Streaming Enchancement
Undesirable Output
- These words are ugly!
#1342] 1 #768] 1 #84] 1 $5,000) 3 & 1 ($1 3 (801) 3 (By 1 (Godwin) 1 (He 1
Homework: (Actual) WordCount
- Modify the Python files. They currently treat words as "strings separated by spaces".
- What if they are instead "contiguous strings of letters"?
- Send me a Github repository:
- New mapper and/or reducer scripts, with
- a README including
- a note on what dataset you used, and
- what mapred command you used,
- You may work in partners on this Homework.
- merrer serves as an example repository - you can fork it.
Something like...
Target Output
- These are words!
a 5883 abaht 1 abandon 3 abandoned 7 abandonment 1 abashed 1 abatement 1 abbey 2 abduction 1 abetted 1 abhor 5 abhorred 14 abhorrence 13 abhorrent 2 abhors 1 abide 6