Two Maps
Week 02
Cloud
Announcements
- Welcome to DATA-599: Cloud Computing!
- This is a segmented lecture - use the course page to come in to pt1 or pt2
- SALEM will do both parts in week 2 and a guest lecture in week 3
- PORTLAND will do one part in week 2 with a guest lecture and part two in week 3.
- Guest Lecture: PNSQC on "Test Automation"
- SALEM: You can exercise an option to remote attend this on Thursday and get out early next Wednesday
- Homework
- The first homework, "Functional", is due this week at 6 PM on Wed/Thr (now).
- These looked good - I'll put 1+ comments in your Colab and @ you.
- If you don't get a comment I either didn't see it or can't comment - you should have a note by Friday 6 PM
- The second homework, "Fold", is due next week at 6 PM on Wed/Thr.
- Make a copy and give me comment/edit permissions. Those you that put your name in the copy title made my life easier but isn't required.
- The first homework, "Functional", is due this week at 6 PM on Wed/Thr (now).
Motiovation, Again
- It is impossible to understate cloud computing as a dominant paradigm *not even just in computing*.
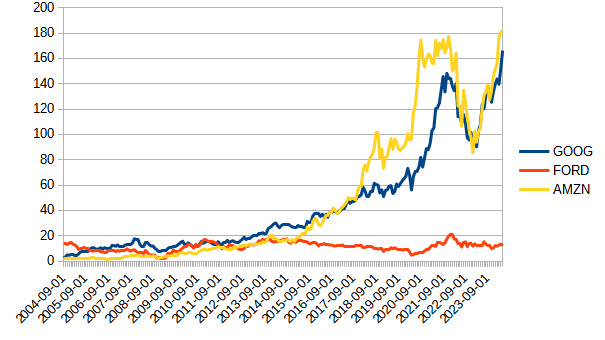
EXAMPLE: CLOUD HOSTED MUSIC SERVICE
- Which would you pick?
- Basically, we have four options:
- Keep my server busy by running one multithreaded application on it
- Keep it busy by running n unthreaded versions of my application as virtual machines, sharing the hardware
- Keep it busy by running n side by side processes, but don’t virtualize
- Keep it busy by running n side by side processes using ✨containers✨
THE WINNER IS…
- Market converging on “container virtualization” with one server process dedicated to each distinct user.
- A single cloud server might host hundreds of these servers. But they are easy to build: you create one music player, and then tell the cloud to run as many “instances” as required.
Why favor container virtualization?
- Code is much easier to write.
- Many people can write a program to play music for a single client – this same insight applies to other programs, too!
- Very easy for the cloud itself to manage: containers are cheap to launch and also to halt, when your customer disconnects
- Containers winning for the reason objects won - easier for management.
- The approach also matches well with modern NUMA computer hardware
My first successful cloud servers were all containerized.
This leads to aN insight!
- Approaches that match programming to hardware win out.
- But what does "win" mean?
- In 2006, when the cloud emerged, we didn’t know the best approach
- Over time, everything had to evolve and be optimized for cloud uses
- Languages
- Coders
- Hardware
- Applications
Spark, our current leader, is built on Scala, a language from 2004. (R is '93, Python '91, JavaScript '95)
The cloud is evolving towards Platforms
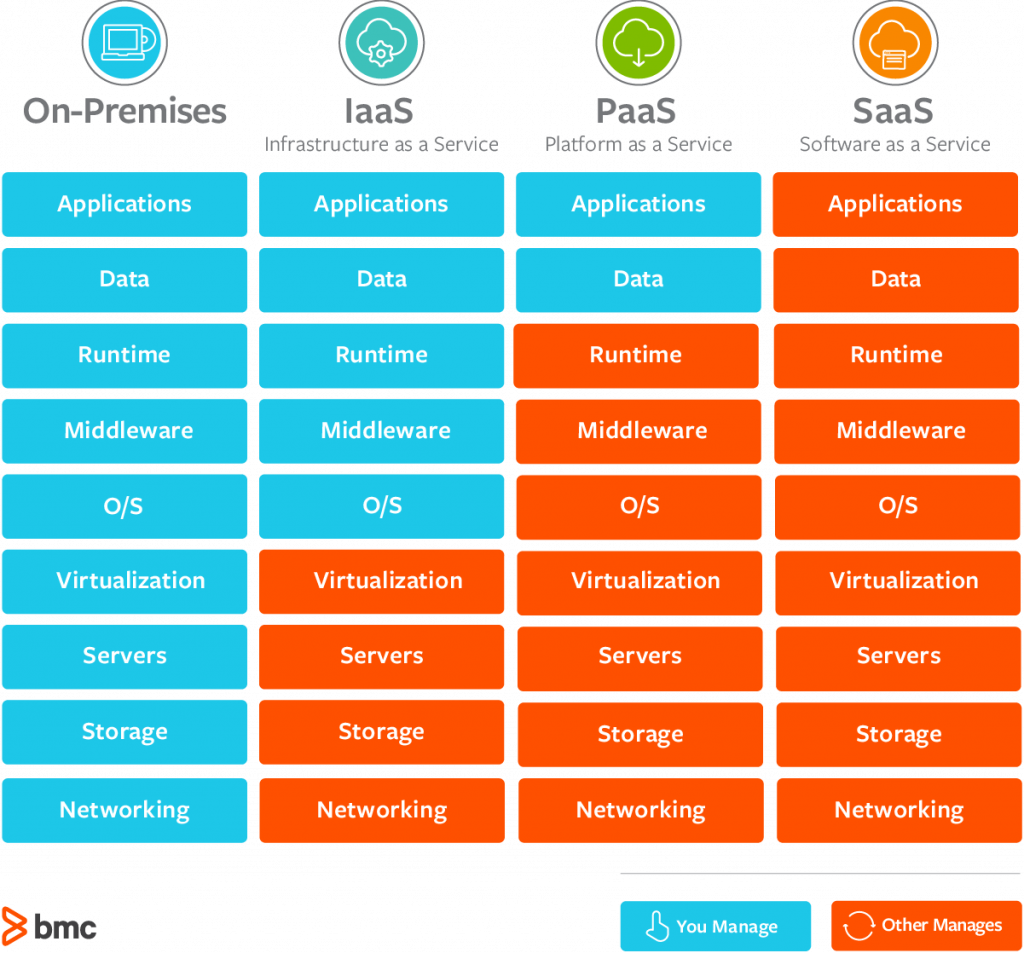
- You’ve seen all the XaaS acronyms.
- Some, like IaaS, basically are “rent a machine, do what you like”.
- GCP Compute Engine, Azure VMs, AWS EC2
- PaaS, meaning “platform as a service” emerged as an alternative
- You never rent a GPU you don't use.
- You don't have to remember to turn off servers.
- Someone who gets paid to know things decides whether to use containers or how.
I've heard CaaS called "IaaS for people who like containers" which I think is probably 80% true.
PAAS CONCEPT
- The cloud favors PaaS.
- Basically, the vendor offers all the standard code, pre-built. They create the platform in ways that perform and scale really well.
I hear "The Salesforce Platform is the world’s number one Platform as a Service (PaaS) solution" (from Salesforce mostly).
New: FAAS
- Or... the cloud favored PaaS.
- In practice, the cloud can do "general purpose" tasks quickly, but can't truly optimize without specialization.
- New trend, Functions as a service (FaaS).
- (This motivated the homework)



AWS Lambda, Google Cloud Functions, Azure Functions
My impression
- I believe we are now seeing a swing back to MapReduce
- It is too easy to understand and too easy to optimize to move away from.
- So today, we focus on maps - or more properly, two maps.

Two Maps (pt 1)
Week 02
Cloud
RECALL
- MapReduce was written in Java and this was odd
- In Java, "Map" is an "interface"
- Interfaces define what methods a class must implement.
- Class are bundles of methods (functions) and fields (values)
- If this is confusing, it is why Java lost (my view)
- In first Lisp, then R, Python, Haskell, "Map" is a function.
- The "Map" in "MapReduce" is the Lisp/R/Python/Haskell/C++ Map.
- You wrote this "Map" for the homework.
>>> def my_map(f, l):
... return [f(i) for i in l]
...
>>> my_map(print, range(10))
0
1
2
3...
One implementation of a Python "map" function.
Interface Map<K,V>
-
- Type Parameters:
- K - the type of keys maintained by this map
- V - the type of mapped values
- All Known Subinterfaces:
- Bindings, ConcurrentMap<K,V>, ConcurrentNavigableMap<K,V>, LogicalMessageContext, MessageContext, NavigableMap<K,V>, SOAPMessageContext, SortedMap<K,V>
- All Known Implementing Classes:
- AbstractMap, Attributes, AuthProvider, ConcurrentHashMap, ConcurrentSkipListMap, EnumMap, HashMap, Hashtable, IdentityHashMap, LinkedHashMap, PrinterStateReasons, Properties, Provider, RenderingHints, SimpleBindings, TabularDataSupport, TreeMap, UIDefaults, WeakHashMap
public interface Map<K,V>An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.This interface takes the place of the Dictionary class, which was a totally abstract class rather than an interface.
Java "Map"
- The Map "interface" corresponds to a series of data structures that implement certain functionalities
- They hold "keys" and "values"
- Each "key" corresponds at at most one "value".
- A Map can be "implemented" as a HashTables (this is what I learned they were called)
- A Map can provide the same functionalities as a "Dictionary".
>>> dct = {'a':1,'b':2,'c':3} >>> dct['a'] 1 >>> type(dct)>>> Python has 'dict' instead of the Map "interface"
RECALL
- MapReduce* was written in Java and this was odd
- In Java, "Map" is an "interface"
- I will never refer to these as "Map" again
- I will instead say "HashTable" or "Dictionary"
- If this is confusing, it is why Java lost (my view)
- "HashTable" is one of the "two maps"
*Hadoop, the open source MapReduce framework I learned was written in Java. It looks like Google MapReduce was in C++, but the code is not public. Map is also not called map in C++...
Introduction to HashTables
- A HashTable,
also known as a hash map, is a data structure that stores key-value pairs. - It allows for fast data retrieval based on keys.
# Something like >>> hash_table = new_ht() >>> hash_table.add('key1', 'value1') >>> hash_table.add('key2', 'value2') >>> hash_table.get('key1') value1Hash Function
- A hash function converts a key into an index in the HashTable.
- In Python, indices are necessarily integers, not "keys".
>>> table = [['a','b','c'],['d','e','f'],['g','h','i']] >>> table[1] ['d','e','f'] - Python offers a built-in 'hash' method (as do most modern languages) to convert most* variables to an integer
>>> hash(1) 1 >>> hash((1,2,3)) 529344067295497451 >>> hash(map) 8795890005933 >>> hash('hi world') -8782460609096434835
It's called hashing because you mash up the information together just like when cooking hash.
Hash Function
- There are good and bad hashes, and they are out of scope for this class.
- SHA512, RSA, and AES are ultra-performant security related hashing algorithms.
- Hash Table performance is based on the "goodness" of the hash, which is different than security.
- For now: a hash is function that takes anything* and returns an integer.
>>> hash(10 ** 20) 848750603811160107
And ideally doesn't return the same integer if the input is an integer.
Modular Hash
- As a rule, the internal "table" in a hash table will be of some fixed size.
- For example, the table of Willamette students would be of size ~4000.
- We don't have 10s of students or 1000000s of students.
- But hash functions may return much larger values than that.
- So, when finding where in a table some key-value pair is stored, we divide the hash value by the table size and take the remainder.
- This is sometimes called "mod" and is denoted as '%' in Python (%% in R)
hash_table = [None for _ in range(10)] hash_table[hash('key1') % len(hash_table)] = ('key1', 'value1') hash_table[hash('key2') % len(hash_table)] = ('key2', 'value2') print(hash_table) - We can see the table, with the key-value pairs.
[None, None, None, ('key2', 'value2'), None, None, None, None, None, ('key1', 'value1')] - Note that they are not adjacent.
>>> print(hash('key1'),hash('key2')) 7359185340662927529 -5201184838170105667
Sidebar: Collisions
- Collisions occur when two keys hash to the same index.
- A "good" hash has this happen infrequently
- One common method to handle collisions is chaining, where each cell in the HashTable points to a list (or any other data structure) of entries.
- Instead of setting the ith index to a key-value pair, we append the pair to a list that starts as empty.
- It's easy to see a collision by using integer values, which Python hashes predictably, as keys.
>>> hash_table = [[] for _ in range(10)] >>> hash_table[hash(11) % len(hash_table)].append((11, 'eleven')) >>> hash_table[hash(21) % len(hash_table)].append((21, 'twenty one')) - We insert two values that happen to hash to the same table index...
>>> hash_table [[], [(11, 'eleven'), (21, 'twenty one')], [], [], [], [], [], [], [], []] - And we have a "collision" - two key-value pairs in the same table index.
Searching for Values
- To find a value, hash the key, find the index, and search the list at that index.
- If we just want the value, we ask for the oneth, that is, index 1, element of the pair.
>>> hash_table[hash('key1') % len(hash_table)][1] 'value1' - There is something sneaky going on here - this is WICKED fast.
Searching for Values
- There is something sneaky going on here - this is WICKED fast.
- Hashing takes about the same amount of time for ANY key
- Looking up a value in a table takes about the same amount of time for any table size
- Takeaway - this works at exa-scale in the cloud.
- VS lists, where to see if something is in them, you have to check the WHOLE list (slow with big data)
>>> start, hash_table, end = time.time(), [[] for _ in range(10 ** 7)], time.time() >>> end-start 2.94462513923645 >>> start, hash_table, end = time.time(), 7 in hash_table, time.time() >>> end-start 0.1309800148010254 >>> start, val, end = time.time(), hash_table[hash(7) % len(hash_table)], time.time() >>> end-start 0.0
- On my PC:
- 3 seconds to make a 10M table
- 0.13 seconds to see if 7 is in it with Python 'in'.
- 0.0 seconds with hash table lookup.
Deleting Key-Value Pairs
- To delete a key-value pair, locate the index using the hash function and either
- Ignoring collisions: Set the location to "None".
- This predictably gives:
[None, None, None, ('key2', 'value2'), None, None, ('key1', 'value1'), None] [None, None, None, ('key2', 'value2'), None, None, None, None]
hash_table = [None for _ in range(8)] hash_table[hash('key1') % len(hash_table)] = ('key1', 'value1') hash_table[hash('key2') % len(hash_table)] = ('key2', 'value2') print(hash_table) hash_table[hash('key1') % len(hash_table)] = None print(hash_table) - This predictably gives:
- Considering collisions: Remove the pair from the list at that index.
- Ignoring collisions: Set the location to "None".
Resizing the HashTable
- We don't always know how big a hash table needs to be when making a new one.
- We would not want to, for example, assume we need 10M entries, take 3 seconds to create a table, then store only 1 value.
- We consider the load factor (number of elements / number of valid indices).
- In general, when this exceeds a certain threshold (usually .5), the hash table is resized to maintain efficiency.
- No code, but:
- Create a new table that is twice as big
- Go through the old table and add everything in the old table to the new table
- Delete the old table.
- We can also shrink tables, such as when load factor goes below .25 or .125.
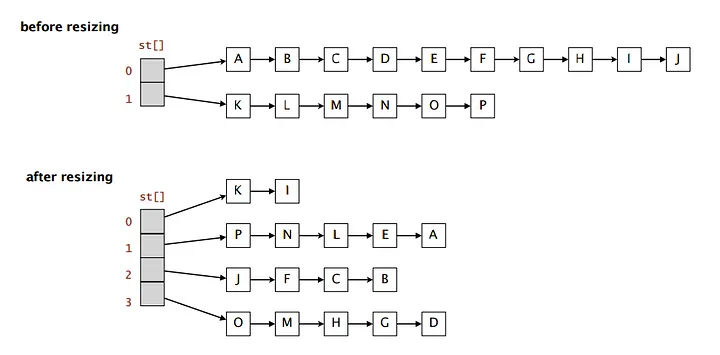
Custom Hash Function
- You can define your own hash function to customize the hashing behavior. Here is a simple example that uses the length of the key.
def custom_hash(key): return len(key) hash_table = [[] for _ in range(10)] hash_table[custom_hash('key1') % len(hash_table)] = ('key1', 'value1') hash_table[custom_hash('k2') % len(hash_table)] = ('k2', 'value2') print(hash_table)
The "Map" Interface-ish
class HashTable: def __init__(self, size=10): # what do you need your table to be? self.table = None def _hash(self, key): # a custom hash - you may use hash() but need more pass def insert(self, key, value): # how can we insert a key-value pair to our table? pass def search(self, key): # given a key, how can we return its corresponding value pass def delete(self, key): # given a key, how can we remove it and it's value pass def _resize(self, size): # OPTIONAL: We may need to resize from time to time... how? # Also... when would this be called? passRECALL
- MapReduce was written in Java and this was odd
- In Java, "Map" is an "interface"
- Our "HashTable" class in Python sorta implements this interface.
- In first Lisp, then R, Python, Haskell, "Map" is a function.
- Our "apply_f_to_everything_in" sorta implements this function.
- R language "lapply" and C++ "std::transform" are other names for the function
def apply_f_to_everything_in(f, data): return [f(d) for d in data]
lapply: Apply a Function over a List or Vector
Description
returns a list of the same length as , each element of which is the result of applying to the corresponding element of .Usage
lapply(X, FUN, …)Arguments
Xa vector (atomic or list) or an object. Other objects (including classed objects) will be coerced by .
// reveal.js pluginsFUNthe function to be applied to each element of : see ‘Details’. In the case of functions like , , the function name must be backquoted or quoted.
lapply()
- In the interest of clarity, we can unambigiously refer to the map function using R "lapply()"
- R (and companion language S) is one of the only languages to not use "map()".
- C++ uses "std::transform()"
- C# uses "ienum.Select()"
- We can also use parens to suggest that something is function.
lst = c(1,2,3) double <- function(x) { return(x * 2) } lapply(lst,double) lapply(c(1,2,3), function(x) x * 2)
We use the keyword "function" instead of keyword "lambda" in R and the function to apply is the second argument, but the computation is identical.
Takeaways
- There are two technologies used in the cloud with ambigious names
- There is a data structure that is fast with big data
- Referred to as a dictionary, hash table, or (confusingly) map
- Dictionaries are one way to implement maps and used in Python
- "Hash table" is an abstract idea and used to implement maps in many languages
- Map as a term just refers to an association between some keys and some values
- Referred to as a dictionary, hash table, or (confusingly) map
- There is a function that applies other functions to collections of data
- Referred to as lapply, transform, or (confusingly) map
- R applies a function to all elements of a collection using "lapply()"
- C++ applies a function to all elements of a collection using "transform()"
- Python applies a function to all elements of a collection using "map()"
- Map as a term just refers to an association between some keys and some values
- Referred to as lapply, transform, or (confusingly) map
- These are the two maps!
>>> d = {'a':1,'b':2} >>> map(lambda x: x * 2, d) <map object at 0x00000231FB586A70>
Applying Python.map() to a Python.dictionary
Last Confusion Bit
We can use maps as maps and maps as maps (sorry)
- We can use a hashtable/dictionary to enumerate the possibilities of a function that we lapply
- Use a dictionary to relate one integer to another, like squares.
>>> squares = {1:1, 2:4, 3:9} >>> squares[2] 4 - The same with a function
>>> squared = lambda x: x * x >>> squared(2) 4 - Wrap the dictionary in a function and lapply
>>> list(map(lambda x: squares[x],[1,2,3,2,1,2,3,2,1])) [1, 4, 9, 4, 1, 4, 9, 4, 1]
Last Confusion Bit
We can use maps as maps and maps as maps (sorry)
- We can use functions to relate keys to values, just like in a hashtable/dictionary
- Use a dictionary to relate days-of-the-week to locations
>>> locs = {"Wed":"SLM", "Thr":"PDX"} >>> locs["Wed"] 'SLM' - The same with a function
>>> def locr(d): ... if d == "Wed": ... return "SLM" ... if d == "Thr": ... return "PDX" ... >>> locr("Wed") 'SLM'
Takeaways
- Ultimately, relating keys to values is a high level concept that can do a lot of work
- Different cloud technologies do this in different ways.
- A lot of artistry of cloud computing is chosing the right way
- Keeping the different ways clear in your mind can be a challenge.

Why did we do this?
- MapReduce works on key-value pairs...
- READ: MapReduce lapplys functions over dictionaries.
- It "maps maps".
We can take a look at the old Hadoop documentation...
Inputs and Outputs
The MapReduce framework operates exclusively on <key, value> pairs, that is, the framework views the input to the job as a set of <key, value> pairs and produces a set of <key, value> pairs as the output of the job, conceivably of different types.
The key and value classes have to be serializable by the framework and hence need to implement the Writable interface. Additionally, the key classes have to implement the WritableComparable interface to facilitate sorting by the framework.
Input and Output types of a MapReduce job:
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
The documentation will latter note that the "combine" stage is optional.
Closing Thoughts: Parallelism
- The reason we use MapReduce is because it parallelizes well.
- lapply
- When we lapply a function to a collection, each instance of the function is independent
- If we have 1000 entries, we can run the function over each 1000 all at the same time and get the same answer
- This means if we have a computer with 1000 cores, we can run 1000x faster.
- Not everything can be parallelized this way:
# rolling average isn't independent [(arr[i] + arr[i+1] + arr[i+2])/3 for i in range(len(arr)-2] - This semester: We will practice thinking about what can and cannot be parallelized.
- lapply
Closing Thoughts: Parallelism
- The reason we use MapReduce is because it parallelizes well.
- Dictionaries
- Combining dictionaries is relatively painless in theory and can be quite quick.
- If we have 1000 dictionaries, we combine pairs until we have 1.
- This means if we have a computer with 500 cores, we can run ~log2(1000)x faster.
- Think about how you can combine hash tables (it's similar to resize perhaps)
- There's no real non-awkward way to do this in Python I know of, but here's an awkward one:
>>> d1 = {1:1, 2:4} >>> d2 = {3:9, 4:16} >>> d1 + d2 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for +: 'dict' and 'dict' >>> {**d1, **d2} {1: 1, 2: 4, 3: 9, 4: 16} >>> - This semester: We will practice thinking about what can and cannot be combined gracefully.
- Dictionaries
Two Maps (pt 2)
Week ~02
Cloud
EXERCISE: HashTable
- Colab link
- Hash tables matter a little, but key-value pairs matter a lot
- So as an exercise we will implement a hash table in Python
- This is the "tasteful amount of fun" from the learning objectives.
- I am sharing a colab document with you. It contains:
- A numpy import statement
- An incomplete HashTable class, containing
- A partial __init__() that you may wish to extend
- An unimplemented _hash() that you may wish to write
- An unimplemented insert() that you must write
- An unimplemented search() that you must write
- An unimplemented delete() that you must write
- An unimplemented _resize() as a bonus/challenge problem
- An unimplemented htapply() that you must write
- 13 cells testing the HashTable, with sample output from the reference solution.
- These are preserved on the following slides, with details.
- So as an exercise we will implement a hash table in Python
- This is an alternative "Hash Table" slide deck if you want to look at how someone else teaches hash tables.
- Hash tables as a rule are not taught in Python since Python has dictionaries, and that deck is based on C++ but I think I fixed it to work for all of you.
EXERCISE: HashTable
- __init__()
- You may add to init but must continue to use a numpy array
- You may use the numpy array in other ways, such as with "empty" - just modify the import
- You may wish to add other fields/attributes and initialize them
- The reference implementation tracks the number of entries (key-value pairs that have been added) and initializes this counter to zero in __init__()
- Fun fact: __init__() is called a "dunder method"
- Init is difficult to test directly, but invoked by the following Colab cell:
ht = HashTable() - An error in this cell is reflective of an error in __init__()
EXERCISE: HashTable
- _hash()
- _hash() is single underscore prefixed to denote
- It should not be exposed to clients using the HashTable, and
- It is easy to tell apart from built-in Python hash() - which it will probably call
- You do not have to use _hash(), but I did.
- You may create other single underscore helper methods, but I did not.
- _hash() is single underscore prefixed to denote
EXERCISE: HashTable
- insert()
- insert() takes two arguments - a key and a value - and stores them
- You should have some way to deal with collisions and make sure it works.
- The reference implementation uses lists, which is tied with "linear probing" for easiest.
- This cell tests insert():
ht.insert("Prof. Calvin","ckdeutschbein") - This cell verifies the insert was performed by inspecting the internal table:
ht._table - It should return a numpy array containing in some way the key value pair ("Prof. Calvin","ckdeutschbein"), such as:
array([None, None, None, None, list([('Prof. Calvin', 'ckdeutschbein')]), None, None, None, None, None], dtype=object) - Once search() is written, this cell will also test both insert() and search()
ht.search("Prof. Calvin"), ht.search("ckdeutschbein"), ht.search("Prof. Cheng") - insert() has no return value, but alters the internal state of the HashTable
- insert() takes two arguments - a key and a value - and stores them
EXERCISE: HashTable
- search()
- search() takes one arguments - a key - and returns a corresponding value or Python None.
- You should have some way to deal with collisions and make sure it works - this probably won't be graceful (but could be)
- The reference implementation traverses a list and inspects the pairs (this is slow to run but fast to think about)
- This cell tests search():
ht.search("Prof. Calvin"), ht.search("ckdeutschbein"), ht.search("Prof. Cheng") - Depending on inserts/deletes, it should return something like:
('ckdeutschbein', None, None) - Once search() is written, one extension is to use time.time() to see how fast it is.
- search() takes one arguments - a key - and returns a corresponding value or Python None.
EXERCISE: HashTable
- delete()
- delete() takes one argument - a key - and removes the key and its value from the HashTable.
- The reference implementation is very similar to insert(), which I would write first
- It's tough to test delete() directly, but I insert() -> search() -> delete() -> search() to verify something once present is now absent.
- That is these calls, across 4 cells:
ht.insert("Prof. Calvin","ckdeutschbein") # returns nothing ht.search("Prof. Calvin") # returns 'ckdeutschbein' ht.delete("Prof. Calvin") # returns nothing ht.search("Prof. Calvin") # returns nothing - You can also examine the internal table, if needed, with ht._table.
- delete() has no return value, but alters the internal state of the HashTable
- delete() takes one argument - a key - and removes the key and its value from the HashTable.
EXERCISE: HashTable
- htapply()
- htapply() takes one argument - a function - and returns a new, different HashTable without altering the existing HashTable.
- This function must take two arguments (a key and a value) and a tuple of size two (a key and a value)
- When testing htapply(), make sure that the original HashTable is preserved
- You will experience many errors at medium-high probability, use print() and type() to test your code
- htapply() over the sample (of professors and willamette ids) must work with extend_email:
- You can test extend email over a solitary key-value pair:
extend_email("Prof. Cheng", "hcheng") - And it must work without issue and produce a novel key-value pair:
('Prof. Cheng', 'hcheng@willamette.edu') - htapply() is correct if and only if it works on the provided extend_email() function.
extend_email = lambda x, y: (x,y+"@willamette.edu") - You can test extend email over a solitary key-value pair:
- htapply() takes one argument - a function - and returns a new, different HashTable without altering the existing HashTable.
EXERCISE: HashTable
- Extension: The C Programming Language
- Ambitious students may implement HashTable as a C language structure in a .c and .h file, of the same name.
- You may work in any environment, but it is possible to use C/C++ compilers within Colab.
- I adhere to a firm coding style on C language structs that you may find interesting, it is documented here.
- If you do C++ you're on your own because I don't use objects, but you can check out the Google style guide.
- I'd include the Colab cell tests as print statements in a C language main() function.
- I've heard (but never checked) that Numpy arrays are similarly performant with C arrays, but we can test relative performance pretty easily if you're looking for something to do.